
Python 基础入门
# Python3 教程
Python 的 3.0 版本,常被称为 Python 3000,或简称Py3K,相对于 Python 的早期版本,这是一个较大的升级。为了不带入过多的累赘,Python 3.0 在设计的时候没有考虑向下兼容。
官方宣布,2020年1月1日,停止Python 2 的更新。
# 查看Python版本
python -V
python --version
2
3
# 第一个Python3.x程序
大多数程序,第一个入门编程代码是Hello World!,以下代码为使用Python输出"Hello World!":
#!/usr/bin/python3
print("Hello, World!")
2
3
Python 常用文件扩展名为.py,可以将上述代码保存在hello.py文件中并使用python命令执行该脚本文件。
python3 hello.py
# Python3 简介
Python 是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。Python 的设计具有很强的可读性,相比其他语言它具有比其他语言更有特色的语法结构。
- Python 是一种解释型语言: 这意味着开发过程种没有了编译这个环节,类似于PHP和Perl语言。
- Python 是交互式语言: 可以在一个 Python 提示符
>>>后直接执行代码 - Python 是面向对象语言: Python 支持面向对象的风格或代码封装在对象的编程技术。
- Python 是初学者的语言: Python 对初级程序员是一种易学的语言,支持广泛的应用程序开发,从简单的文字处理到网站开发再到游戏。
# Python 发展历史
Python 是由 Guido van Rossum 在上世纪八十年代末和九十年代初,在荷兰国家数学和计算机科学研究所设计出来的,Python 本身也是由诸多其他语言发展而来的,包括ABC、Modula-3、C、C++、Algol-68、SmallTalk、Unix Shell和其他脚本语言等。与Perl语言类似,Python源代码同样遵循GPL(GNU General Public License)协议。现在Python由一个核心团队在维护,Guido van Rossum仍然占据着至关重要的作用。
Python 2.0 于2000年10月16日发布,增加实现了完整的垃圾回收,并且支持Unicode。
Python 3.0 于2008年12月3日发布,此版完全不兼容之前的Python源码,不过,很多新特性后来也被移植到旧的Python 2.6/2.7版本。
Python 3.0 版本,常被称为Python 3000,或简称Py3K,相对于Python的早期版本,是一个较大的升级,Python 2.7 被确定为最后一个Python 2.x版本,它除了支持Python 2.x语法外,还支持部分Python 3.1语法。
# Python 特点
- 易于学习: Python有相对较少的关键字,结构简单,语法定义明确。
- 易于阅读: Python代码清晰
- 易于维护: 源代码容易维护
- 一个广泛的标准库: Python的优势之一就是有丰富的库,跨平台,在UNIX,Windows和Macintosh上兼容很好
- 互动模式: 支持互动的测试和调试代码片段
- 可移植: 基于其开放源代码的特性,Python已经被移植到许多平台
- 可扩展: 如果需要一段运行快而关键的代码,或者需要编写一些不愿开放的算法,可以使用C或C++完成那部分程序,然后用Python进行调用
- 数据库: 提供所有主要的商业数据库的接口
- GUI编程: Python支持GUI可以创建和移植到许多系统调用
- 可嵌入: 可以将Python嵌入到C/C++程序,让程序获得脚本化的能力
# Python 应用
- Youtube - 视频社交网站
- Reddit - 社交分享网站
- Dropbox - 文件分享服务
- 豆瓣网 - 图书、唱片、电影等文化产品的资料数据库网站
- 知乎 - 一个问答网站
- 果壳 - 一个泛科技主体网站
- Bottle - Python微Web框架
- EVE - 网络游戏EVE大量使用Python进行开发
- Blender - 使用Python作为建模工具与GUI语言的开源3D绘图软件
- Inkscape - 一个开源的SVG矢量图形编辑器
# Python3 基础语法
# 编码
默认情况下,Python 3源码文件以UTF-8编码,所有字符串都是unicode字符串,当然也可以为源码文件指定不同的编码:
# -*- coding: cp-1252 -*-
上述定义允许在源文件中使用Windows-1252字符集中的字符编码,对应适合语言为保加利亚语、白俄罗斯语、马其顿语、俄语、塞尔维亚语。
# 标识符
- 第一个字符必须是字母表中字母或下划线
_ - 标识符的其他部分由字母、数字和下划线组成
- 标识符对大小写敏感
在Python3中,可以用中文作为变量名,非ASCII标识符也是允许的。
# Python 保留字
保留字即关键字,不能把它们用作任何标识符名称,Python的标准库提供了一个keyword模块,可以输出当前版本的所有关键字:
#!/usr/bin/python3
import keyword
print("Hello, World!")
print(keyword.kwlist)
2
3
4
5

# 注释
Python中单行注释以#开头,实例如下:
#!/usr/bin/python3
# 第一个注释
print ("Hello, Python!") # 第二个注释
2
3
4
多行注释可以用多个#,还有'''和"""
#!/usr/bin/python3
import keyword
# 第一行注释
# 第二行注释
'''
第三行注释
第四行注释
'''
"""
第五行注释
第六行注释
"""
print("Hello, World!")
print(keyword.kwlist)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 行与缩进
Python最具特色的就是使用缩进来表示代码块,不需要使用大括号{},缩进的空格数是可变的,但是同一个代码块的语句必须包含相同的缩进空格数,如下:
if True:
print ("True")
else:
print ("False")
2
3
4
以下代码最后一行语句缩进数的空格不一致,会报错:
if True:
print ("Answer")
print ("True")
else:
print ("Answer")
print ("False") # 缩进不一致,会导致运行错误
2
3
4
5
6
File "test.py", line 6
print ("False") # 缩进不一致,会导致运行错误
^
IndentationError: unindent does not match any outer indentation level
2
3
4
5
# 多行语句
Python 通常是一行写完一条语句,但如果语句很长,可以使用反斜杠\来实现多行语句,如:
total = item_one + \
item_two + \
item_three
2
3
在[]、{}、()中的多行语句,不需要使用反斜杠\,如:
total = ['item_one', 'item_tow', 'item_three',
'item_four', 'item_five']
2
# 数字(Number)类型
Python中数字有四种类型: 整数、布尔型、浮点数和复数
- int(整数): 如1,只有一种整数类型int,表示为长整型,没有python2中的Long
- bool(布尔): 如True
- float(浮点数): 如1.23、3E-2
- complex(复数): 如
1 + 2j、1.1 + 2.2j
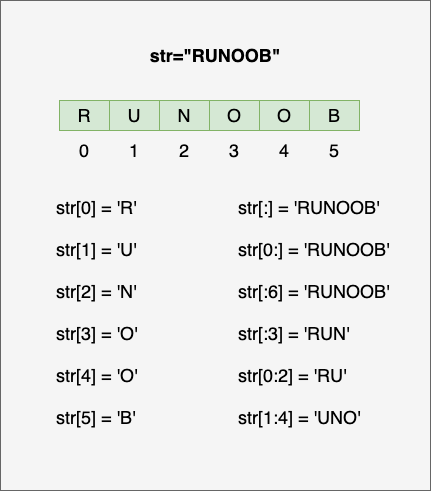
# 字符串(String)
- Python中单引号
'和双引号"使用完全相同 - 使用三引号
'''或"""可以指定一个多行字符串 - 转义符
\ - 反斜杠可以用来转义,使用
r可以让反斜杠不发生转义,如r"this is a line with \n"则\n会显示,并不是换行 - 按字面意义级联字符串,如
"this " "is " "string"会被自动转换为this is string - 字符串可以用
+运算符连接在一起,用*运算符重复 - Python中的字符串有两种索引方式,从左往右以
0开始,从右往左以-1开始 - Python中的字符串不能改变
- Python没有单独的字符类型,一个字符就是长度为1的字符串
- 字符串切片
str[start:end],其中start(包含)是切片开始的索引,end(不包含)是切片结束的索引 - 字符串的切片可以加上步长参数
step,语法格式如下:str[start:end:step]
word = '字符串'
sentence = "这是一个句子。"
paragraph = """这是一个段落,
可以由多行组成"""
2
3
4
#!/usr/bin/python3
str='123456789'
print(str) # 输出字符串
print(str[0:-1]) # 输出第一个到倒数第二个的所有字符
print(str[0]) # 输出字符串第一个字符
print(str[2:5]) # 输出从第三个开始到第六个的字符(不包含)
print(str[2:]) # 输出从第三个开始后的所有字符
print(str[1:5:2]) # 输出从第二个开始到第五个且每隔一个的字符(步长为2)
print(str * 2) # 输出字符串两次
print(str + '你好') # 连接字符串
print('----------------------------------------')
print('hello\nrunoob') # 使用反斜杠(\)+n转义特殊字符
print(r'hello\nrunoob') # 在字符串前面添加一个 r,表示原始字符串,不发生转义
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
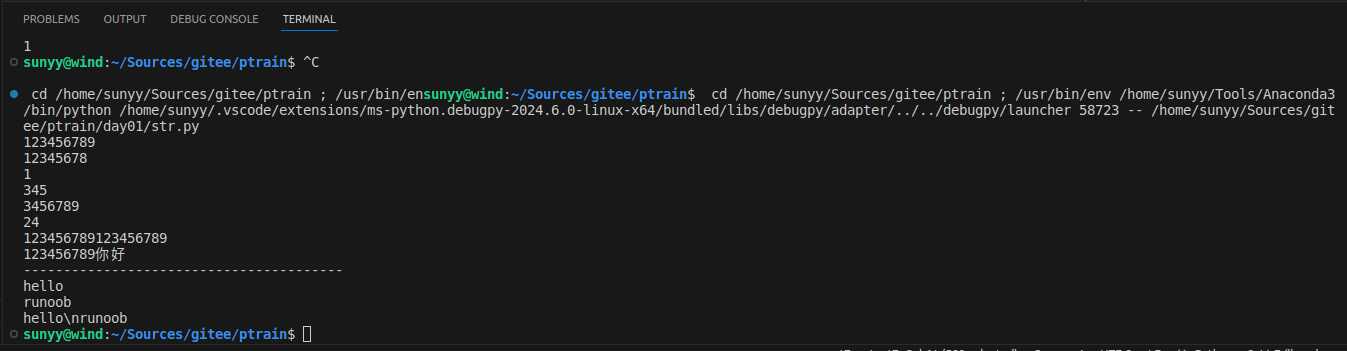
这里的r指raw,即raw string,会自动将反斜杠转义,例如:
print('\n') # 输出空行
print(r'\n') # 输出 \n
2
# 空行
函数之间或类的方法之间用空行分隔,表示一段新的代码的开始,类和函数入口之间也用一行空行分隔,以突出函数入口的开始。
空行与代码缩进不同,空行并不是Python语法的一部分,书写时不插入空行,Python解释器运行时也不会出错,但是空行的作用在于分隔两段不同功能或含义的代码,便于日后代码的维护或重构。空行也是代码的一部分。
# 等待用户输入
执行下面的程序在按回车键后就会等待用户输入:
#!/usr/bin/python3
input("\n\n按下 enter 键后退出。")
2
3
以上代码,\n\n在结果输出前会输出两个新的空行,一旦用户按下enter键时,程序将退出
# 同一行显示多条语句
Python 可以在同一行中使用多条语句,语句之间使用分号;分隔,如:
#!/usr/bin/python3
import sys; x = 'runoob'; sys.stdout.write(x + '\n')
2
3
# 多个语句构成代码组
缩进相同的一组语句构成一个代码块,称之为代码组。如if、while、def和class这样的符合语句,首行以关键字开始,以冒号(:)结束,改行之后的一行或多行代码构成代码组,将首行以及后面的代码组称为一个子句。
如下:
if expression :
suite
elif expression :
suite
else :
suite
2
3
4
5
6
# print 输出
print默认输出是换行的,如果要实现不换行需要在变量末尾加上end="":
#!/usr/bin/python3
x="a"
y="b"
# 换行输出
print( x )
print( y )
print('---------')
# 不换行输出
print( x, end=" " )
print( y, end=" " )
print()
2
3
4
5
6
7
8
9
10
11
12
13
# import 与 from ... import
在python用import或者from ... import来导入响应的模块:
- 将整个模块(somemodule)导入,格式为:
import somemodule - 从某个模块中导入某个函数,格式为:
from somemodule import somefunction - 从某个模块中导入多个函数,格式为:
from somemodule import firstfunc, secondfunc, thirdfunc - 将某个模块中的全部函数导入,格式为:
from somemodule import *
import sys
print('================Python import mode==========================')
print ('命令行参数为:')
for i in sys.argv:
print (i)
print ('\n python 路径为',sys.path)
2
3
4
5
6
from sys import argv,path # 导入特定的成员
print('================python from import===================================')
print('path:',path) # 因为已经导入path成员,所以此处引用时不需要加sys.path
2
3
4
# Python3 基本数据类型
Python中的变量不需要声明,每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建。在Python中,变量就是变量,没有类型,我们所说的类型是变量所指的内存中对象的类型。
等号(=)用来给变量赋值。
等号(=)运算符左边是一个变量名,等号(=)运算符右边是存储在变量中的值,如:
#!/usr/bin/python3
counter = 100 # 整型变量
miles = 1000.0 # 浮点型变量
name = "runoob" # 字符串
print (counter)
print (miles)
print (name)
2
3
4
5
6
7
8
9
- 多个变量赋值
Python允许同时为多个变量赋值,如:
a = b = c = 1
以上实例,创建一个整型对象,值为1,从后向前赋值,三个变量被赋予相同的数值。当然也可以为多个对象指定多个变量,如:
a, b, c = 1, 2, "runoob"
以上实例,两个整型对象1和2分配给变量a和b,字符串对象"runoob"分配给变量c。
# 标准数据类型
Python3中常见的数据类型有:
Number(数字)String(字符串)bool(布尔类型)List(列表)Tuple(元组)Set(集合)Dictionary(字典)
Python3的六个标准数据类型中:
- 不可变数据(3个):
Number、String、Tuple - 可变数据(3个):
List、Set、Dictionary
# Number (数字)
Python3支持int、float、bool、complex,在Python3里,只有一种整数类型int,表示为长整型,没有python2中的Long,像大多数语言一样,数值类型的赋值和计算都是很直观的,内置的type()函数可以用来查询变量所指的对象类型。
>>> a, b, c, d = 20, 5.5, True, 4+3j
>>> print(type(a), type(b), type(c), type(d))
<class 'int'> <class 'float'> <class 'bool'> <class 'complex'>
2
3
此外还可以用isinstance来判断:
>>> a = 111
>>> isinstance(a, int)
True
>>>
2
3
4
isinstance和type的区别在于
type()不会认为子类、父类为同一种类型isinstance()会认为子类、父类为同一种类型
>>> class A:
... pass
...
>>> class B(A):
... pass
...
>>> isinstance(A(), A)
True
>>> type(A()) == A
True
>>> isinstance(B(), A)
True
>>> type(B()) == A
False
2
3
4
5
6
7
8
9
10
11
12
13
14
Python3中,bool是int的子类,True和False可以和数字相加,True==1和False==0都会返回True,可以通过is来判断类型:
>>> issubclass(bool, int)
True
>>> True==1
True
>>> False==0
True
>>> True+1
2
>>> False+1
1
>>> 1 is True
False
>>> 0 is False
False
2
3
4
5
6
7
8
9
10
11
12
13
14
在Python2中是没有布尔类型的,它用数字0表示False,用1表示True
当指定一个值时,Number对象就会被创建:
var1 = 1
var2 = 10
2
也可以使用del语句删除一些对象的引用,其语法为:
del var1[, var2[, var3[..., varN]]]
可以通过del语句删除单个或多个对象,如:
del var
del var_a, var_b
2
数值运算:
>>> 5 + 4 # 加法
9
>>> 4.3 - 2 # 减法
2.3
>>> 3 * 7 # 乘法
21
>>> 2 / 4 # 除法,得到一个浮点数
0.5
>>> 2 // 4 # 除法,得到一个整数
0
>>> 17 % 3 # 取余
2
>>> 2 ** 5 # 乘方
32
2
3
4
5
6
7
8
9
10
11
12
13
14
注意
- Python可以同时为多个变量赋值,如
a, b = 1, 2 - 一个变量可以通过赋值指向不同类型的对象
- 数值的除法包含两个运算符
/返回一个浮点数,//返回一个整数 - 在混合计算时,Python会把整型转换为浮点数
int | float | complex |
|---|---|---|
| 10 | 0.0 | 3.14j |
| 100 | 15.20 | 45.j |
| -786 | -21.9 | 9.322e-36j |
| 080 | 32.3e+18 | .876j |
| -0490 | -90. | -.6545+0J |
| -0x260 | -32.54e100 | 3e+26J |
| 0x69 | 70.2E-12 | 4.53e-7j |
Python还支持附属,复数由实数部分和虚数部分构成,可以用a + bj,或者complex(a, b)表示,复数的实部a和虚部b都是浮点型。
# String (字符串)
Python中的字符串用单引号'和双引号"括起来,同时使用反斜杠\转义特殊字符。字符串的截取的语法格式如下:
变量[头下标:尾下标]
索引值以0为开始值,-1位从末尾的开始位置

加号+是字符串的连接符,型号*表示赋值当前字符串,与之结合的数字为复制的次数,实例如下:
#!/usr/bin/python3
str = 'Runoob' # 定义一个字符串变量
print(str) # 打印整个字符串
print(str[0:-1]) # 打印字符串第一个到倒数第二个字符(不包含倒数第一个字符)
print(str[0]) # 打印字符串的第一个字符
print(str[2:5]) # 打印字符串第三到第五个字符(包含第五个字符)
print(str[2:]) # 打印字符串从第三个字符开始到末尾
print(str * 2) # 打印字符串两次
print(str + "TEST") # 打印字符串和"TEST"拼接在一起
2
3
4
5
6
7
8
9
10
11
Python使用反斜杠\转义特殊字符,如果不想让反斜杠发生转义,可以在字符串前面添加一个r,表示原始字符串。
另外,反斜杠\可以作为续行符,表示下一行是上一行的延续,也可以使用"""..."""或者'''...'''跨越多行。注意,Python没有单独的字符类型,一个字符就是长度为1的字符串,与C字符串不同,Python字符串不能被改变,向一个索引位置赋值,比如word[0] = 'm'会导致错误。
注意
- 反斜杠可以用来转义,使用
r可以让反斜杠不发生转义 - 字符串可以用
+运算符连接,用*运算符重复 - Python中的字符串有两种索引方式,从左往右以0开始,从右往左以-1开始
- Python中的字符串不能改变
# bool (布尔类型)
布尔类型即True或False,在Python中,True和False都是关键字,表示布尔值,布尔类型可以用来控制程序的流程,比如判断某个条件是否成立,或者在某个条件满足时执行某段代码。布尔类型特点:
- 布尔类型只有两个值:
True和False - 布尔类型可以和其他数据类型进行比较,比如数字,字符串等。在比较时,Python会将
True视为1,False视为0 - 布尔类型可以和逻辑运算符一起使用,包括
and、or和not,这些运算符可以用来组合多个布尔表达式,生成一个新的布尔值 - 布尔类型也可以被转换秤其他数据类型,比如整数、浮点数和字符串,在转换时,
True为1,False为0
a = True
b = False
# 比较运算符
print(2 < 3) # True
print(2 == 3) # False
# 逻辑运算符
print(a and b) # False
print(a or b) # True
print(not a) # False
# 类型转换
print(int(a)) # 1
print(float(b)) # 0.0
print(str(a)) # "True"
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
注意
在Python中,所有非零的数字和非空的字符串、列表、元组等数据类型都被视为True,只有0、空字符串、空列表、空元组等被视为False,因此在进行布尔类型转换时,需要注意数据类型的真假性。
# List (列表)
List(列表)是Python中使用最频繁的数据类型,列表可以完成大多数集合类的数据结构实现,列表中元素的类型可以不相同,它支持数字、字符串甚至可以包含列表(所谓嵌套)。列表是写在方括号[]之间、用逗号分隔的元素列表,和字符串一样,列表同样可以被索引和截取,列表被截取后返回一个包含所需元素的新列表。
变量[头下标:尾下标]
索引值以0位开始值,-1位从末尾的开始位置
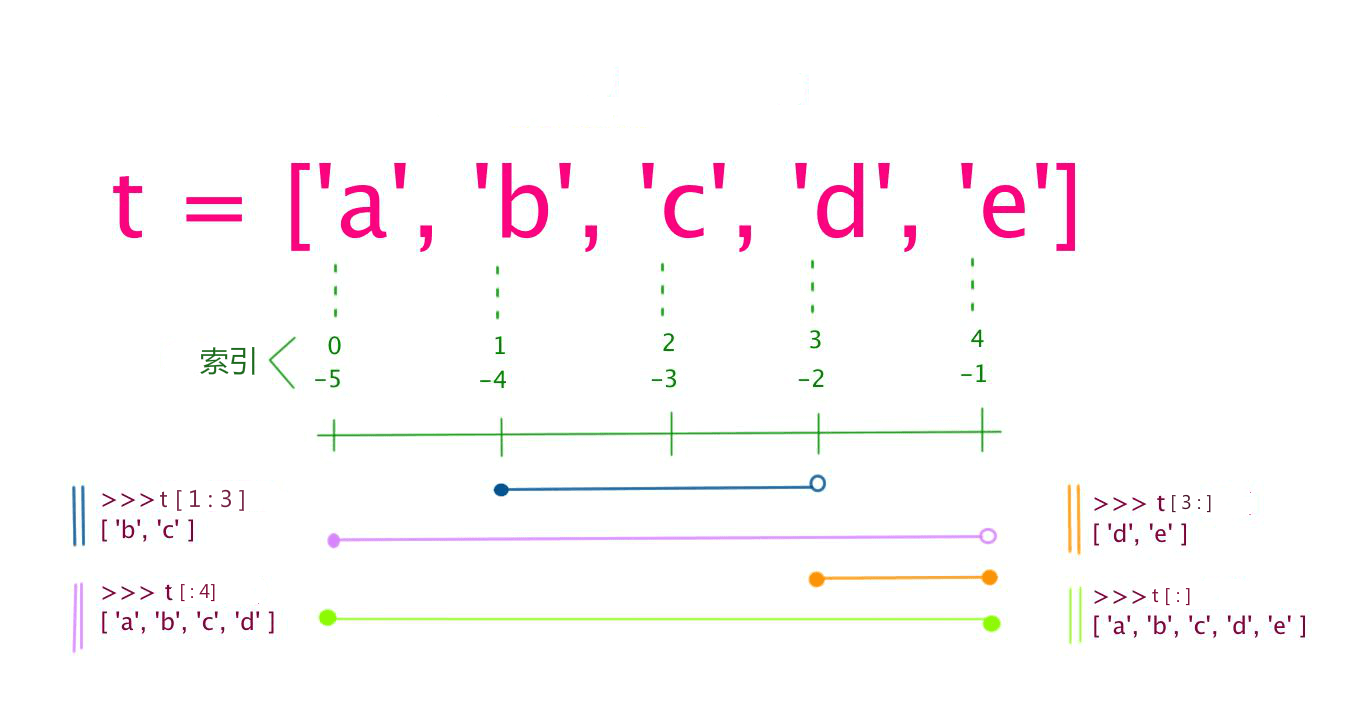
加号+是列表连接运算符,星号*是重复操作,如下:
#!/usr/bin/python3
list = ['abcd', 786, 2.23, 'runoob', 70.2] # 定义一个列表
tinylist = [123, 'runoob']
print(list) # 打印整个列表
print(list[0]) # 打印列表第一个元素
print(list[1:3]) # 打印列表第二个到第四个元素(不包含第四个元素)
print(list[2:]) # 打印列表从第三个元素开始到末尾
print(tinylist * 2) # 打印tinylist列表两次
print(list + tinylist) # 打印两个列表拼接在一起
2
3
4
5
6
7
8
9
10
11
与Python字符串不一样的是,列表中的元素是可以改变的:
>>> a = [1, 2, 3, 4, 5, 6]
>>> a[0] = 9
>>> a[2:5] = [13, 14, 15]
>>> a
[9, 2, 13, 14, 15, 6]
>>> a[2:5] = [] # 将对应的元素值设置为 []
>>> a
[9, 2, 6]
2
3
4
5
6
7
8
List内置了很多方法,例如append()、pop()等等
注意
- 列表写在方括号之间,元素用逗号隔开
- 和字符串一样,列表可以被索引和切片
- 列表可以使用
+操作费进行拼接 - 列表中的元素是可以改变的
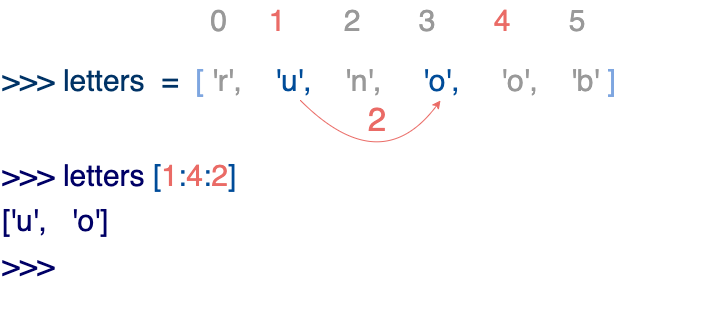
Python列表截取可以接收第三个参数,参数作用是截取的步长,以下实例在索引1到索引4的位置并设置步长为2,来截取字符串:
如果第三个参数为负数表示逆向截取,以下实例用于翻转字符串:
#!/usr/bin/python3
def reverseWords(input):
# 通过空格将字符串分隔,将各个单词分隔为列表
inputWords = input.split(" ")
# 翻转字符串
# 假设列表 list = [1, 2, 3, 4]
# list[0] = 1, list[1] = 2, 而 -1 表示最后一个元素 list[-1] = 4 (与 list[3] = 4 一样)
# inputWords[-1::-1] 有三个参数
# 第一个参数 -1 表示最后一个元素
# 第二个参数为空,表示移动到列表末尾
# 第三个参数为步长, -1 表示逆向
inputWords = inputWords[-1::-1]
# 重新组合字符串
output = ' '.join(inputWords)
return output
if __name__ == "__main__":
input = 'I like runoob'
rw = reverseWords(input)
print(rw)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
runoob like I
# Tuple (元组)
元组(tuple)与列表类似,不同之处在于元组的元素不能修改,元组写在小括号()里,元素之间用逗号隔开,元组中的元素类型也可以不相同:
#!/usr/bin/python3
tuple = ('abcd', 786, 2.23, 'runoob', 70.2)
tinytuple = (123, 'runoob')
print(tuple) # 输出完整元组
print(tuple[0]) # 输出元组的第一个元素
print(tuple[1:3]) # 输出从第二个元素开始到第三个元素
print(tuple[2:]) # 输出从第三个元素开始的所有元素
print(tinytuple * 2) # 输出两次元组
print(tuple + tinytuple) # 连接元组
2
3
4
5
6
7
8
9
10
11
元组与字符串类似,可以被索引且下标索引从0开始-1为从末尾开始的位置,也可以进行截取。其实,可以把字符串看作一种特殊的元组。
>>> tup = (1, 2, 3, 4, 5, 6)
>>> print(tup[0])
1
>>> print(tup[1:5])
(2, 3, 4, 5)
>>> tup[0] = 11 # 修改元组元素的操作是非法的
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
>>>
2
3
4
5
6
7
8
9
10
虽然tuple的元素不可改变,但它可以包含可变的对象,比如list列表。构造包含0个或1个元素的元组比较特殊,有一些额外的语法规则:
tup1 = () # 空元组
tup2 = (20,) # 一个元素,需要在元素后添加逗号
2
如果想要创建只有一个元素的元组,需要注意在元素后面添加一个逗号,以区分它是一个元组而不是一个普通的值,这是因为在没有逗号的情况下,Python会将括号解释为数学运算中的括号,而不是元组的表示。如果不添加逗号,如下,它将被解释为一个普通的值而不是元组:
not_a_tuple = (42) # not_a_tuple将是整数类型而不是元组类型
string、list和tuple都属于sequence(序列)
- 与字符串一样,元组的元素不能修改
- 元组可以被索引和切片,方法一样
- 注意构造包含0或1个元素的元组的特殊语法规则
- 元组也可以使用
+操作符进行拼接
# Set (集合)
Python中的集合Set是一种无序、可变的数据类型,用于存储唯一的元素,集合中的元素不会重复,并且可以进行交集、并集、差集等常见的集合操作。在Python中,集合使用大括号{}表示,元素之间用逗号,分隔。另外,也可以使用set()函数创建集合。
注意
创建一个空集合必须用set()而不是{},因为{}是用来创建一个空字典
格式:
parame = {value01, value02, ...}
# 或者
set(value)
2
3
#!/usr/bin/python3
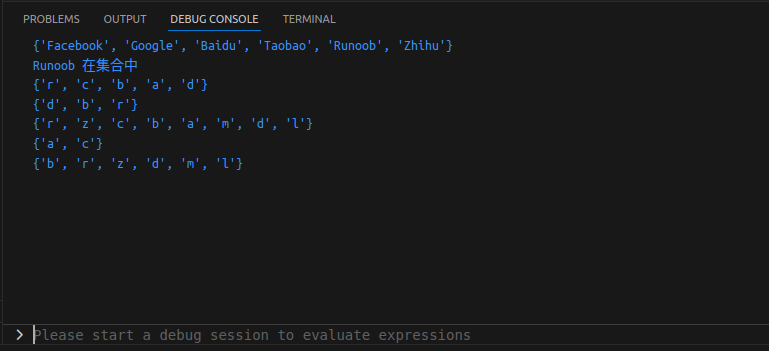
sites = {'Google', 'Taobao', 'Runoob', "Facebook", "Zhihu", "Baidu"}
print(sites) # 输出集合,重复的元素被自动去掉
# 成员测试
if "Runoob" in sites :
print("Runoob 在集合中")
else :
print("Runoob 不在集合中")
# set 可以进行集合运算
a = set("abracadabra")
b = set("alacazam")
print(a)
print(a - b) # a 和 b 的差集
print(a | b) # a 和 b 的并集
print(a & b) # a 和 b 的交集
print(a ^ b) # a 和 b 中不同时存在的元素
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# Dictionary (字典)
字典(dictionary)是Python中另一个非常有用的内置数据类型。列表是有序的对象集合,字典是无序的对象集合,两者之间的区别在于: 字典当中的元素是通过键来存取的,而不是通过偏移存取。字典是一种映射类型,字典用{}标识,它是一个无序的键(key):值(value)的集合。键(key)必须使用不可变类型,在同一个字典中,键必须是唯一的。
#!/usr/bin/python3
dict = {}
dict["one"] = "1 - 菜鸟教程"
dict[2] = "2 - 菜鸟工具"
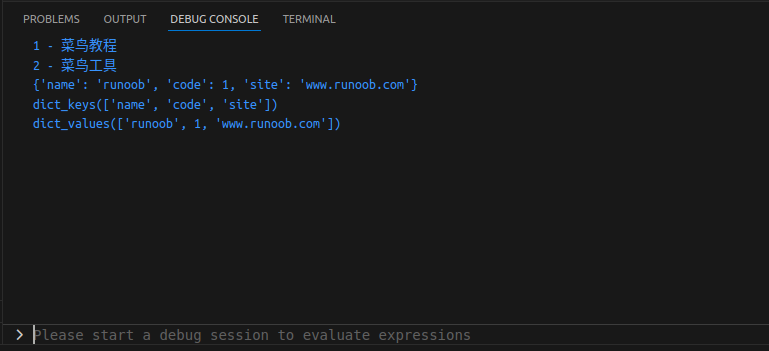
tinydict = {"name": "runoob", "code": 1, "site": "www.runoob.com"}
print(dict["one"]) # 输出键为 one 的值
print(dict[2]) # 输出键为 2 的值
print(tinydict) # 输出完整的字典
print(tinydict.keys()) # 输出所有的键
print(tinydict.values()) # 输出所有值
2
3
4
5
6
7
8
9
10
11
12
13
构造函数dict()可以直接从键值对序列中构建字典如下:
>>> dict([('Runoob', 1), ('Google', 2), ('Taobao', 3)])
{'Runoob': 1, 'Google': 2, 'Taobao': 3}
>>> {x: x**2 for x in (2, 4, 6)}
{2: 4, 4: 16, 6: 36}
>>> dict(Runoob=1, Google=2, Taobao=3)
{'Runoob': 1, 'Google': 2, 'Taobao': 3}
2
3
4
5
6
{x: x**2 for x in (2, 4, 6)}该代码使用的是字典推导式,更多推导式内容可以参考: Python推导式。另外,字典类型也有一些内置的函数,如clear()、keys()、values()等
注意
- 字典是一种映射类型,它的元素是键值对
- 字典的关键字必须为不可变类型,且不能重复
- 创建空字典使用
{}
# bytes 类型
在Python3中,bytes类型表示的是不可变的二进制序列(byte sequence)。与字符串类型不同的是,bytes类型中的元素是整数值(0到255之间的整数),而不是Unicode字符。bytes类型通常用于处理二进制数据,比如图像文件、音频文件、视频文件等。在网络编程中,也经常使用bytes类型来传输二进制数据。
创建bytes对象的方式有多种,最常见的方式是使用b前缀: 此外,也可以使用bytes()函数将其他类型的对象转换为bytes类型,bytes()函数的第一个参数是要转换的对象,第二个参数是编码方式,如果省略第二个参数,则默认使用UTF-8编码:
x = bytes("hello", encoding = "utf-8")
与字符串类型类似,bytes类型也支持许多操作和方法,如切片、拼接、查找、替换等等。同时,由于bytes类型是不可变的,因此在进行修改操作时需要创建一个新的bytes对象,例如:
x = b"hello"
y = x[1:3] # 切片操作,得到 b"el"
z = x + b"world" # 拼接操作,得到 b"helloworld"
2
3
需要注意的是,bytes类型中的元素是整数值,因此在进行比较操作时需要使用相应的整数值。例如:
x = b"hello"
if x[0] == ord("h") :
print("The first element is 'h'")
2
3
其中 ord() 函数用于将字符转换为相应的整数值。
有时候,需要对数据内置的类型进行转换,数据类型的转换,只需要将数据类型作为函数名即可,以下几个内置的函数可以执行数据类型之间的转换,这写函数返回一个新的对象,表示转换的值。
| 函数 | 描述 |
|---|---|
int(x[,base]) | 将x转换为一个整数 |
float(x) | 将x转换到一个浮点数 |
complex(real[,imag]) | 创建一个复数 |
str(x) | 将对象x转换为字符串 |
repr(x) | 将对象x转换为表达式字符串 |
eval(str) | 用来计算在字符串中的有效python表达式,并返回一个对象 |
tuple(s) | 将序列s转换为一个元组 |
list(s) | 将序列s转换为一个列表 |
set(s) | 转换为可变集合 |
dict(d) | 创建一个字典,d必须是一个(key,value)元组序列 |
frozenset(s) | 转换为不可变集合 |
chr(x) | 将一个整数转换为一个字符 |
ord(x) | 将一个字符转换为它的整数值 |
hex(x) | 将一个整数转换为一个十六进制字符串 |
oct(x) | 将一个整数转换为一个八进制字符串 |
# Python3 数据类型转换
有时候,需要对数据内置的类型进行转换,数据类型的转换,一般情况下只需要将数据类型作为函数名即可。Python数据类型转换可以分为两种:
- 隐式类型转换 - 自动完成
- 显式类型转换 - 需要使用类型函数来转换
# 隐式类型转换
在隐式类型转换中,Python会自动将一种数据类型转换为另一种数据类型,不需要手动干预,如:
num_int = 123
num_flo = 1.23
num_new = num_int + num_flo
print("num_int 数据类型为:", type(num_int))
print("num_flo 数据类型为:", type(num_flo))
print("num_new 值为:", num_new)
print("num_new 数据类型为:", type(num_new))
2
3
4
5
6
7
8
9
10
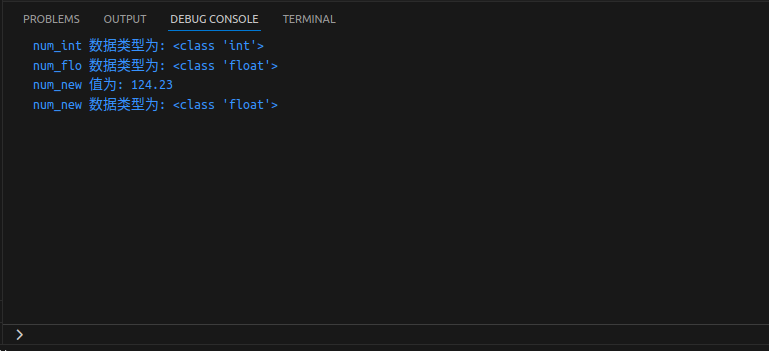
代码解析
- 实例中对两个不同数据类型的变量
num_int和num_flo进行相加运算,并存储在变量num_new中 - 然后查看三个变量的数据类型
- 输出结果中,
num_int是整型(integer),num_flo是浮点型(float) - 新的变量
num_new是浮点型(float),因为Python会将较小的数据类型转换为较大的数据类型,以避免数据丢失
在比如以下实例:
#!/usr/bin/python3
num_int = 123
num_str = "456"
print("num_int 数据类型为:", type(num_int))
print("num_str 数据类型为:", type(num_str))
print(num_int + num_str)
2
3
4
5
6
7
8
9
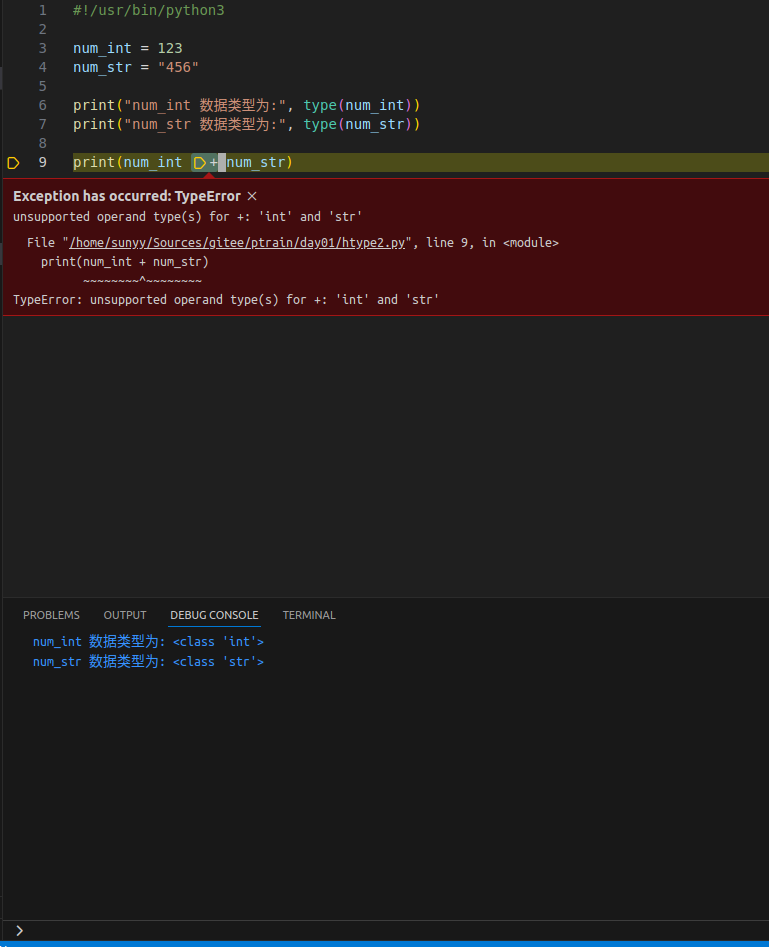
从输出中可以看出,整型和字符串类型运算结果会报错,输出TypeError。Python在这种情况下无法使用隐式转换,但是可以使用显式转换。
# 显式类型转换
在显式类型转换中,用户将对象的数据类型转换为所需的数据类型,使用int()、float()、str()等预定义函数来执行显式类型转换,如下:
x = int(1) # x 输出结果为 1
y = int(2.8) # y 输出结果为 2
z = int("3") # z 输出结果为 3
2
3
x = float(1) # x 输出结果为 1.0
y = float(2.8) # y 输出结果为 2.8
z = float("3") # z 输出结果为 3.0
w = float("4.2")# w 输出结果为 4.2
2
3
4
x = str("s1") # x 输出结果为 "s1"
y = str(2) # y 输出结果为 "2"
z = str(3.0) # z 输出结果为 "3.0"
2
3
整型和字符串类型进行运算,可以用显式类型转换完成:
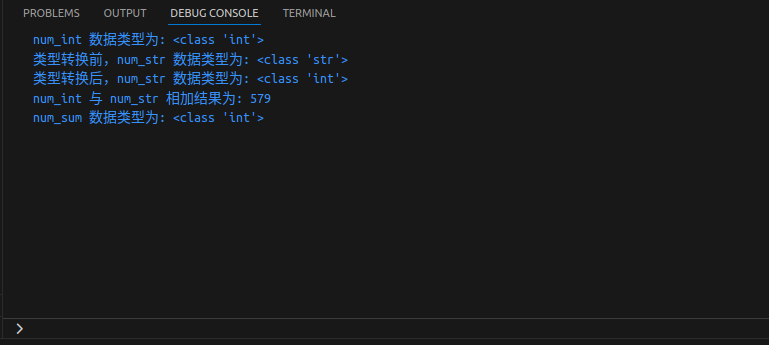
#!/usr/bin/python3
num_int = 123
num_str = "456"
print("num_int 数据类型为:", type(num_int))
print("类型转换前,num_str 数据类型为:", type(num_str))
num_str = int(num_str)
print("类型转换后,num_str 数据类型为:", type(num_str))
num_sum = num_int + num_str
print("num_int 与 num_str 相加结果为:", num_sum)
print("num_sum 数据类型为:", type(num_sum))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# Python3 注释
在 Python3 中,注释不会影响程序的执行,但是会使代码更易于阅读和理解。有单行注释和多行注释。
Python中单行注释以#开头,如:
# 这是一个注释
print("Hello, World!")
2
#后面的所有文本都被视为注释,不会被解释执行
**多行注释用三个单引号'''或者三个双引号"""将注释括起来,如:
#!/usr/bin/python3
'''
这是多行注释,用三个单引号
这是多行注释,用三个单引号
这是多行注释,用三个单引号
'''
print("Hello, World!")
2
3
4
5
6
7
8
#!/usr/bin/python3
"""
这是多行注释,用三个双引号
这是多行注释,用三个双引号
这是多行注释,用三个双引号
"""
print("Hello, World!")
2
3
4
5
6
7
8
注意
虽然多行字符串在这里被当做多行注释使用,但它实际上是一个字符串,只要不使用它,就不会影响程序的运行。这些字符串在代码中可以被放置在一些位置,而不引起实际的执行,从而达到注释的效果。
# 拓展说明
在Python中,多行注释是由三个单引号或三个双引号来定义的,而且这种注释不能嵌套使用,当开始多行注释时,Python会一直将后续的行都当做注释,直到遇到另一组三个单引号或三个双引号。嵌套多行注释会导致语法错误。如:
'''
这是外部的多行注释
可以包含一些描述性的内容
'''
这是尝试嵌套的多行注释
会导致语法错误
'''
'''
2
3
4
5
6
7
8
9
在上面的例子中,内部的三个单引号并没有被正确识别为多行注释的结束,而是被解释为普通的字符串,这将导致代码结构的不正确,最终导致语法错误。如果需要在注释中包含嵌套结构,推荐使用单行注释,单行注释可以嵌套在多行注释中,而且不会引起语法错误:
'''
这是外部的多行注释
可以包含一些描述性的内容
# 这是内部的单行注释
# 可以嵌套在多行注释中
'''
2
3
4
5
6
7
# Python3 运算符
# 算术运算符
假设变量 a = 10,变量 b = 21:
| 运算符 | 描述 | 实例 |
|---|---|---|
+ | 加: 两个对象相加 | a + b = 31 |
- | 减: 得到负数或是一个数减去另一个数 | a - b = -11 |
* | 乘: 两个数相乘或是返回一个被重复若干次的字符串 | a * b = 210 |
/ | 除: x 除以 y | b / a = 2.1 |
% | 取模: 返回除法的余数 | b % a = 1 |
** | 幂: 返回 x 的 y 次幂 | a**b = 10的21次方 |
// | 取整数: 往小的方向取整数 | 9 // 2 = 4 ,-9 // 2 = -5 |
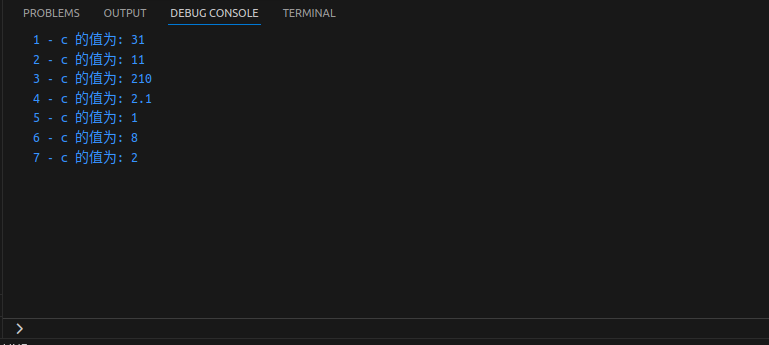
#!/usr/bin/python3
a = 21
b = 10
c = 0
c = a + b
print("1 - c 的值为:", c)
c = a - b
print("2 - c 的值为:", c)
c = a * b
print("3 - c 的值为:", c)
c = a / b
print("4 - c 的值为:", c)
c = a % b
print("5 - c 的值为:", c)
# 修改变量a、b、c
a = 2
b = 3
c = a ** b
print("6 - c 的值为:", c)
a = 10
b = 5
c = a//b
print("7 - c 的值为:", c)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# 比较运算符
变量a = 10,变量b = 20:
| 运算符 | 描述 | 实例 |
|---|---|---|
== | 等于: 比较对象是否相等 | a == b 返回 False |
!= | 不等于: 比较两个对象是否不相等 | a != b 返回 True |
> | 大于: 返回 x 是否大于 y | a > b 返回 False |
< | 小于: 返回 x 是否小于 y。所有比较运算符返回1表示真,返回0表示假,这分别与特殊的变量True和False等价 | a < b 返回 True |
>= | 大于等于: 返回 x 是否大于等于 y | a >= b 返回 False |
<= | 小于等于: 返回 x 是否小于等于 y | a <= b 返回 True |
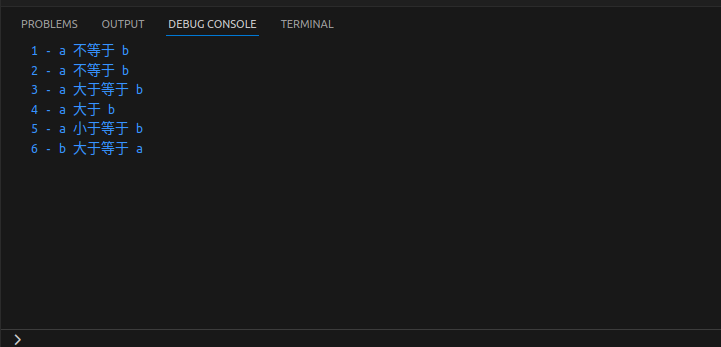
#!/usr/bin/python3
a = 21
b = 10
c = 0
if (a == b):
print("1 - a 等于 b")
else:
print("1 - a 不等于 b")
if (a != b):
print("2 - a 不等于 b")
else:
print("2 - a 等于 b")
if (a < b):
print("3 - a 小于 b")
else:
print("3 - a 大于等于 b")
if (a > b):
print("4 - a 大于 b")
else:
print("4 - a 小于等于 b")
# 修改变量 a 和 b 的值
a = 5
b = 20
if (a <= b):
print("5 - a 小于等于 b")
else:
print("5 - a 大于 b")
if (b >= a):
print("6 - b 大于等于 a")
else:
print("6 - b 小于 a")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# 赋值运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
= | 简单的赋值运算符 | c = a + b将a + b的运算结果赋值给c |
+= | 加法赋值运算符 | c += a等效于c = c + a |
-= | 减法赋值运算符 | c -= a等效于c = c - a |
*= | 乘法赋值运算法 | c *= a等效于c = c * a |
/= | 除法赋值运算符 | c /= a等效于c = c / a |
%= | 取模赋值运算符 | c %= a等效于c = c % a |
**= | 幂赋值运算符 | c **= a等效于c = c ** a |
//= | 取整除赋值运算符 | c //= a等效于c = c // a |
:= | 海象运算符,这个运算符的主要目的是在表达式中同时进行赋值和返回赋值的值, Python3.8新增运算符 | 在这个实例中,赋值表达式可以避免调用len()两次:
|
#!/usr/bin/python3
a = 21
b = 10
c = 0
c = a + b
print("1 - c 的值为: ", c)
c += a
print("2 - c 的值为: ", c)
c *= a
print("3 - c 的值为: ", c)
c /= a
print("4 - c 的值为: ", c)
c = 2
c %= a
print("5 - c 的值为: ", c)
c **= a
print("6 - c 的值为: ", c)
c //= a
print("7 - c 的值为: ", c)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27

在Python3.8及更高版本中,引入了一种新的语法特性,称为海象运算符(Walrus Operator),它使用:=符号,这个运算符的主要目的是在表达式中同时进行赋值和返回赋值的值。使用海象运算符可以在一些情况下简化代码,尤其是在需要在表达式中使用赋值结果的情况下,这对于简化循环条件或表达式中的重复计算很有用。
#!/usr/bin/pyton3
# 传统写法
n = 10
if n > 5:
print(n)
# 海象运算符
if (n := 10) > 5:
print(n)
2
3
4
5
6
7
8
9
if (n := 10) > 5:: 这是使用海象运算符(:=)的写法,海象运算符在表达式中进行赋值操作(n := 10): 将变量n赋值为10,同时返回这个赋值结果> 5: 检查赋值后的n是否大于5,如果条件为真,则执行接下来的代码块。
print(n): 如果条件为真,打印变量n的值
:::info 海象运算符的优点
- 海象运算符(
:=)允许在表达式内部进行赋值,这可以减少代码的重复,提高代码的可读性和简洁性。 - 在上述例子中,传统写法需要单独一行来赋值n,然后在
if语句中进行条件检查,而使用海象运算符的写法可以在if语句中直接进行赋值和条件检查。 :::
# 位运算符
按位运算符是把数字看作二进制来进行计算,其规则如下:
下表中变量a为60,b为13,二进制格式如下:
a = 0011 1100
b = 0000 1101
-----------------
a&b = 0000 1100
a|b = 0011 1101
a^b = 0011 0001
~a = 1100 0011
2
3
4
5
6
7
8
9
10
11
12
13
| 运算符 | 描述 | 实例 |
|---|---|---|
& | 按位与运算符: 参与运算的两个值,如果两个相应位都为1,则该位的结果为1,否则为0 | (a & b)输出结果为12,二进制: 0000 1100 |
\| | 按位或运算符: 只要对应的二个二进位有一个为1,结果位就为1 | (a \| b)输出结果为61,二进制: 0011 1101 |
^ | 按位异或运算符: 当两对应的二进位不同时,结果为1 | (a ^ b)输出结果为49,二进制: 0011 0001 |
~ | 按位取反运算符: 对数据的每个二进位取反,即把1变为0,把0变为1。~x类似于-x-1 | (~a)输出结果为-61,二进制: 1100 0011,在一个有符号二进制数的补码形式。 |
<< | 左移运算符: 运算数的各二进位全部左移若干位,由<<右边的数指定移动的位数,高位丢弃,低位补0 | a<<2输出结果为240,二进制: 1111 0000 |
>> | 右移运算符: 把>>左边的运算数的各二进位全部右移若干位, >>右边的数指定移动的位数 | a>>2输出结果为15,二进制: 0000 1111 |
#!/usr/bin/python3
a = 60 # 60 = 0011 1100
b = 13 # 13 = 0000 1101
c = 0
c = a & b # 12 = 0000 1100
print("1 - c 的值为: ", c)
c = a | b # 61 = 0011 1101
print("2 - c 的值为: ", c)
c = a ^ b # 49 = 0011 0001
print("3 - c 的值为: ", c)
c = ~a # -61 = 1100 0011
print("4 - c 的值为: ", c)
c = a << 2 # 240 = 1111 0000
print("5 - c 的值为: ", c)
c = a >> 2 # 15 = 0000 1111
print("6 - c 的值为: ", c)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23

# 逻辑运算符
Python支持逻辑运算符,以下假设变量a为10,b为20:
| 运算符 | 逻辑表达式 | 描述 | 实例 |
|---|---|---|---|
and | x and y | 布尔与-如果x为False,x and y返回x的值,否则返回y的计算值。 | (a and b)返回20。 |
or | x or y | 布尔或-如果x为True,它返回x的值,否则它返回y的计算值。 | (a or b)返回10。 |
not | not x | 布尔非-如果x为True,返回False。如果x为False,它返回True。 | not (a and b)返回False。 |
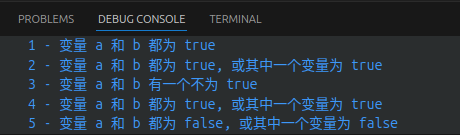
#!/usr/bin/python3
a = 10
b = 20
if (a and b):
print("1 - 变量 a 和 b 都为 true")
else:
print("1 - 变量 a 和 b 有一个不为 true")
if (a or b):
print("2 - 变量 a 和 b 都为 true, 或其中一个变量为 true")
else:
print("2 - 变量 a 和 b 都不为 true")
# 修改变量 a 的值
a = 0
if (a and b):
print("3 - 变量 a 和 b 都为 true")
else:
print("3 - 变量 a 和 b 有一个不为 true")
if (a or b):
print("4 - 变量 a 和 b 都为 true, 或其中一个变量为 true")
else:
print("4 - 变量 a 和 b 都不为 true")
if not(a and b):
print("5 - 变量 a 和 b 都为 false, 或其中一个变量为 false")
else:
print("5 - 变量 a 和 b 都为 true")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# 成员运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
in | 如果在指定的序列中找到值返回True,否则返回False | x在y序列中,如果x在y序列中返回True |
not in | 如果在指定的序列中没有找到值返回True,否则返回False | x不在y序列中,如果x不在y序列中返回True |
#!/usr/bin/python3
a = 10
b = 20
list = [1, 2, 3, 4, 5]
if (a in list):
print("1 - 变量 a 在给定的列表 list 中")
else:
print("1 - 变量 a 不在给定的列表 list 中")
if (b not in list):
print("2 - 变量 b 不在给定的列表 list 中")
else:
print("2 - 变量 b 在给定的列表 list 中")
# 修改变量 a 的值
a = 2
if (a in list):
print("3 - 变量 a 在给定的列表 list 中")
else:
print("3 - 变量 a 不在给定的列表 list 中")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22

# 身份运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
is | is是判断两个标识符是不是引用自一个对象 | x is y,类似id(x) == id(y),如果引用的是同一个对象则返回True,否则返回False |
is not | is not是判断两个标识符是不是引用自不同对象 | x is not y,类似id(x) != id(y),如果引用的不是同一个对象则返回结果True,否则返回False |
注
id()函数用于获取对象内存地址。
#!/usr/bin/python3
a = 20
b = 20
if (a is b):
print("1 - a 和 b 有相同的标识")
else:
print("1 - a 和 b 没有相同的标识")
if (id(a) == id(b)):
print("2 - a 和 b 有相同的标识")
else:
print("2 - a 和 b 没有相同的标识")
# 修改变量 b 的值
b = 30
if (a is b):
print("3 - a 和 b 有相同的标识")
else:
print("3 - a 和 b 没有相同的标识")
if (a is not b):
print("4 - a 和 b 没有相同的标识")
else:
print("4 - a 和 b 有相同的标识")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26

is 与 == 区别
is用于判断两个变量引用对象是否为同一个,==用于判断引用变量的值是否相等。
# 运算符优先级
以下表格列出了从最高到最低优先级的所有运算符,相同单元格内的运算具有相同的优先级,运算符均指二元运算,除非特别指出。相同单元格内的运算符从左至右分组(除了幂运算是从右至左分组):
| 运算符 | 描述 |
|---|---|
(expressions...),[expressions...],{key: value...},{expressions...},x[index],x[index:index],x(arguments...),x.attribute | 圆括号的表达式 |
i[index],x[index:index],x(arguments...),x.attribute | 读取,切片,调用,属性引用 |
await x | await表达式 |
** | 乘方(指数) |
+x, -x, ~x | 正,负,按位非NOT |
*, @, /, //, % | 乘,矩阵乘,除,整除,取余 |
+, - | 加和减 |
<<, >> | 移位 |
& | 按位与AND |
^ | 按位异或XOR |
\| | 按位或OR |
in, not in, is, is not, <, <=, >, >=, !=, == | 比较运算,包括成员监测和标识号监测 |
not x | 逻辑非NOT |
and | 逻辑与AND |
or | 逻辑或OR |
if -- else | 条件表达式 |
lambda | lambda表达式 |
:= | 赋值表达式 |
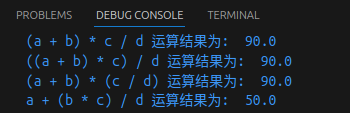
#!/usr/bin/python3
a = 20
b = 10
c = 15
d = 5
e = 0
e = (a + b) * c / d # (30 * 15) / 5
print("(a + b) * c / d 运算结果为: ", e)
e = ((a + b) * c) /d # (30 * 15) / 5
print("((a + b) * c) / d 运算结果为: ", e)
e = (a + b) * (c / d) # (30) * (15 / 5)
print("(a + b) * (c / d) 运算结果为: ", e)
e = a + (b * c) / d # 20 + (150 / 5)
print("a + (b * c) / d 运算结果为: ", e)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
and 拥有更高优先级
x = True
y = False
z = False
if x or y and z:
print("yes")
else:
print("no")
2
3
4
5
6
7
8
以上实例先计算y and z并返回False,然后x or False返回True
Python3已不支持<>运算符,可以使用!=代替。
# Python3 数字(Number)
Python数字数据类型用于存储数值。数据类型是不允许改变的,这意味着如果改变数字数据类型的值,将重新分配内存空间。以下实例在变量赋值时Number对象被创建:
var1 = 1
var2 = 10
2
也可以使用del语句删除一些数字对象的引用。del语句的语法是:
del var1[,var2[,var3[...,varN]]]
可以通过使用del语句删除单个或多个对象的引用,例如:
del var
del var_a, var_b
2
Python支持三种不同的数值类型:
- 整型(
int): 通常被称为是整型或整数,是正或负整数,不带小数点。Python3整型是没有大小限制的,可以当作Long类型使用,所以Python3没有Python2的Long类型。布尔(bool)是整型的子类型。 - 浮点型(
float): 浮点型由整数部分与小数部分组成,浮点型也可以使用科学计数法表示(2.5e2=2.5×102=250) - 复数(
complex): 复数由实数部分和虚数部分构成,可以用a + bj或者complex(a, b)表示,复数的实部a和虚部b都是浮点型。
# Python 数字类型转换
有时候,需要对数据内置的类型进行转换,数据类型的转换,只需要将数据类型作为函数名即可。
int(x): 将x转换为一个整数float(x): 将x转换到一个浮点数complex(x): 将x转换到一个复数,实数部分为x,虚数部分为0.complex(x, y): 将x和y转换到一个复数,实数部分为x,虚数部分为y,x和y是数字表达式。
# Python 数字运算
Python解释器可以作为一个简单的计算器,可以在解释器里输入一个表达式,它将输出表达式的值。表达式的语法很直白,+,-,*和/
注意
在不同的机器上浮点运算的结果可能会不一样,在整数除法中,除法/总是返回一个浮点数,如果只想得到整数的结果,丢弃可能的分数部分,可以使用运算符//,//得到的并不一定是整数类型的数,它与分母分子的数据类型有关系。=用于给变量赋值,赋值之后,除了下一个提示符,解释器不会显示任何结果。Python可以使用**操作来进行幂运算,变量在使用前必须先定义(即赋予变量一个值),否则会出现错误。不同类型的数混合运算时会将整数转换为浮点数。在交互模式中,最后被输出的表达式结果被赋值给变量_,_变量应被用户视为只读变量。
# 数学函数
| 函数 | 返回值(描述) |
|---|---|
abs(x) | 返回数字的绝对值,如abs(-10)返回10 |
ceil(x) | 返回数字的上入整数,如math.ceil(4.1)返回5 |
cmp(x, y) | 如果x < y返回-1,如果x == y返回0,如果x > y返回1.Python3已废弃,使用x > y和x < y替换 |
exp(x) | 返回e的x次幂(ex),如math.exp(1)返回2.718281828459045 |
fabs(x) | 以浮点数形式返回数字的绝对值,如math.fabs(-10)返回10.0 |
floor(x) | 返回数字的下舍整数,如math.floor(4.9)返回4 |
log(x) | 如math.log(math.e)返回1.0,math.log(100, 10)返回2.0 |
log10(x) | 返回以10为基数的x的对数,如math.log10(100)返回2.0 |
max(x1, x2, ...) | 返回给定参数的最大值,参数可以为序列 |
min(x1, x2, ...) | 返回给定参数的最小值,参数可以为序列 |
modf(x) | 返回x的整数部分与小数部分,两部分的数值符号与x相同,整数部分以浮点型表示 |
pow(x, y) | x**y运算后的值 |
round(x, [,n]) | 返回浮点数x的四舍五入值,如给出n值,则代表舍入到小数点后的位数。其实准确的说是保留值将保留到离上一位更近的一端 |
sqrt(x) | 返回数字x的平方根 |
# 随机数函数
随机数可以用于数学,游戏,安全等领域中,还经常被嵌入到算法中,用以提高算法效率,并提高程序的安全性。
| 函数 | 描述 |
|---|---|
choice(seq) | 从序列的元素中随机挑选一个元素,比如random.choice(range(10)),从0到9中随机挑选一个整数。 |
randrange([start,]stop[,step]) | 从指定范围内,按指定基数递增的集合中获取一个随机数,基数默认值为1 |
random() | 随机生成下一个实数,它在[0, 1]范围内 |
seed([x]) | 改变随机数生成器的种子seed,如果你不了解其原理,不必特别去设定seed,Python会自己选择seed |
shuffle(lst) | 将序列的所有元素随机排序 |
uniform(x, y) | 随机生成下一个实数,它在[x, y]范围内 |
# 三角函数
| 函数 | 描述 |
|---|---|
acos(x) | 返回x的反余弦弧度值 |
asin(x) | 返回x的反正弦弧度值 |
atan(x) | 返回x的反正切弧度值 |
atan2(y, x) | 返回给定的X及Y坐标值的反正切值 |
cos(x) | 返回x的弧度的余弦值 |
hypot(x, y) | 返回欧几里德范数sqrt(x*x + y*y) |
sin(x) | 返回x弧度的正弦值 |
tan(x) | 返回x弧度的正切值 |
degrees(x) | 将弧度转换为角度,如degrees(math.pi/2),返回90.0 |
radians(x) | 将角度转换为弧度 |
# 数学常量
| 函数 | 描述 |
|---|---|
pi | 数学常量pi(圆周率,一般以π表示) |
e | 数学常量e,即自然常数 |
# Python3 字符串
字符串是Python中最常用的数据类型,可以使用引号('或")来创建字符串。创建字符串很简单,只要为变量分配一个值即可。例如:
var1 = 'Hello World!'
var2 = "Runoob"
2
# Python 访问字符串中的值
Python不支持单字符类型,单字符在Python中也是作为一个字符串使用。Python访问子字符串,可以使用方括号[]来截取字符串,字符串的截取的语法格式如下:
变量[头下标:尾下标]
索引值以0为开始值,-1为从末尾的开始位置。

如下实例:
#!/usr/bin/python3
var1 = "Hello World!"
var2 = "Runoob"
print("var1[0]: ", var1[0])
print("var2[1:5]: ", var2[1:5])
2
3
4
5
6
7

# Python 字符串更新
可以截取字符串的一部分并与其他字段拼接,如下实例:
#!/usr/bin/python3
var1 = 'Hello World!'
print("已更新字符串: ", var1[:6] + 'Runoob!')
2
3
4
5

# Python 转义字符
在需要在字符中使用特殊字符时,python用反斜杠\转义字符。如下表:
| 转义字符 | 描述 | 实例 |
|---|---|---|
\(在行尾时) | 续行符 | >>> print("line1 \ line2 \ line3") line1 line2 line3 |
\\ | 反斜杠符号 | >>> print("\\") \ |
\' | 单引号 | >>> print('\'') ' |
\" | 双引号 | >>> print("\"") " |
\a | 响铃 | >>> print("\a") 执行后电脑有响声 |
\b | 退格(Backspace) | >>> print("Hello \b World!") Hello World! |
\000 | 空 | >>> print(\000) |
\n | 换行 | >>> print("\n") |
\v | 纵向制表符 | >>> print("Hello \v World!") Hello World! |
\t | 横向制表符 | >>> print("Hello \t World!") Hello World! |
\r | 回车,将\r后面的内容一到字符串开头,并逐一替换开头部分的字符,直至将\r后面的内容完全替换完成 | |
\f | 换页 | |
\yyy | 八进制数,y代表0~7的字符,例如: \012代表换行 | |
\xyy | 十六进制数,以\x开头,y代表的字符,例如: \x0a代表换行 | |
\other | 其他的字符以普通格式输出 |
注意: 上面的转义不一定有效
print("line1 \
line2 \
line3")
print("\\")
print('\'')
print("\"")
print("\a")
print("Hello \b World!")
print("\000")
print("\n")
print("Hello \v World!")
print("Hello \t World!")
print('Hello\rWorld!')
print('google runoob taobao\r123456')
print("Hello \f World!")
print("\110\145\154\154\157\40\127\157\162\154\144\41")
print("\x48\x65\x6c\x6c\x6f\x20\x57\x6f\x72\x6c\x64\x21")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
import time
for i in range(101):
print("\r{:3}%".format(i), end=' ')
time.sleep(0.05)
2
3
4
5

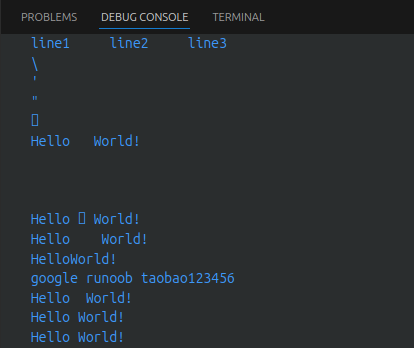
以下实例,使用了不同的转义字符来演示单引号、换行符、制表符、退格符、换页符、ASCII、二进制、八进制和十六进制的效果:
print('\'Hello, world!\'') # 输出: 'Hello, world!'
print("Hello, world!\nHow are you?") # 输出: Hello, world!
# How are your?
print("Hello, world!\tHow are you?") # 输出: Hell, world! How are you?
print("Hello,\b world!") # 输出: Hello world!
print("Hello,\f world!") # 输出:
# Hello,
# world!
print("A 对应的 ASCII 值为: ", ord('A')) # 输出: A 为 A 的 ASCII 代码
print("\x41 为 A 的 ASCII 代码") # 输出: A 为 A 的 ASCII 代码
decimal_number = 42
binary_number = bin(decimal_number) # 十进制转换为二进制
print('转换为二进制: ', binary_number) # 转换为二进制: 0b101010
octal_number = oct(decimal_number) # 十进制转换为二进制
print('转换为八进制: ', octal_number) # 转换为八进制: 0o52
hexadecimal_number = hex(decimal_number) # 十进制转换为十六进制
print('转换为十六进制: ', hexadecimal_number) # 转换为十六进制: 0x2a
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
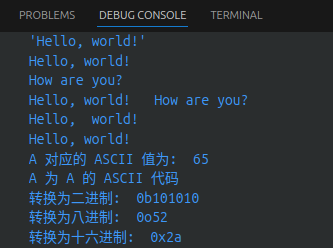
# Python 字符串运算符
下表实例变量 a 值为字符串"Hello",b 变量值为"Python":
| 操作符 | 描述 | 实例 |
|---|---|---|
+ | 字符串连接 | a + b输出结果: HelloPython |
* | 重复输出字符串 | a*2输出结果: HelloHello |
[] | 通过索引获取字符串字符 | a[1]输出结果e |
[:] | 截取字符串中的一部分,遵循左闭右开原则,str[0:2]是不包含第3个字符的。 | a[1:4]输出结果ell |
in | 成员运算符-如果字符串中包含给定的字符返回True | 'H' in a输出结果True |
not in | 成员运算符-如果字符串中不包含给定的字符返回True | 'M' not in a输出结果True |
r/R | 原始字符串-原始字符串: 所有的字符串都是直接按照字面的意思来使用,没有转义特殊或不能打印的字符。原始字符串除在字符串的第一个引号加上字母r(可以大小写)以外,与普通字符串有着几乎完全相同的语法。 | print(r'\n')``print(R'\n') |
% | 格式字符串 |
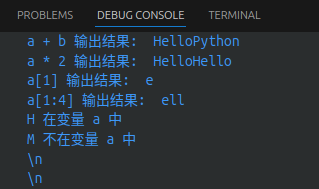
a = "Hello"
b = "Python"
print("a + b 输出结果: ", a + b)
print("a * 2 输出结果: ", a * 2)
print("a[1] 输出结果: ", a[1])
print("a[1:4] 输出结果: ", a[1:4])
if ("H" in a):
print("H 在变量 a 中")
else:
print("H 不在变量 a 中")
if ("M" not in a):
print("M 不在变量 a 中")
else:
print("M 在变量 a 中")
print(r'\n')
print(R'\n')
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# Python 字符串格式化
Python支持格式化字符串的输出,尽管这样可能会用到非常复杂的表达式,但最基本的用法是将一个值插入到一个有字符串格式符%s的字符串中。在Python中,字符串格式化使用与C中sprintf函数一样的语法。
print("我叫 %s 今年 %d 岁!" % ('小明', 10))
| 符号 | 描述 |
|---|---|
%c | 格式化字符及其ASCII码 |
%s | 格式化字符串 |
%d | 格式化整数 |
%u | 格式化无符号整数 |
%o | 格式化无符号八进制数 |
%x | 格式化无符号16进制数 |
%X | 格式化无符号16进制数(大写) |
%f | 格式化浮点数字,可指定小数点后的精度 |
%e | 用科学计数法格式化浮点数 |
%E | 作用同%e,用科学计数法格式化浮点数 |
%g | %f和%e的简写 |
%G | %f和%E的简写 |
%p | 用16进制数格式化变量的地址 |
格式化操作符辅助指定:
| 符号 | 功能 |
|---|---|
* | 定义宽度或小数点精度 |
- | 用做左对齐 |
+ | 在正数前面显示加号(+) |
<sp> | 在正数前面显示空格 |
# | 在八进制数前面显示零(0),在16进制前面显示0x或者0X(取决于用的是x还是X) |
0 | 显示的数字前面填充0而不是默认的空格 |
% | %%输出一个单一的% |
(var) | 映射变量(字典参数) |
m.n. | m是显示的最小总宽度,n是小数点后的位数(如果可用的话) |
Python2.6开始,新增了一种格式化字符串的函数str.format(),它增强了字符串格式化的功能。
# Python 三引号
Python三引号允许一个字符串跨多行,字符串中可以包含换行符、制表符以及其他特殊字符。实例如下:
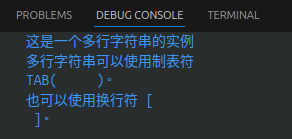
para_str = """这是一个多行字符串的实例
多行字符串可以使用制表符
TAB( \t )。
也可以使用换行符 [ \n ]。
"""
print(para_str)
2
3
4
5
6
三引号让程序员从引号和特殊字符串的泥潭里面解脱出来,自始至终保持一小块字符串的格式是所谓的所见即所得格式。一个典型的用例是,当需要一块HTML或者SQL时,这时用字符串组合,特殊字符串转义将会非常的繁琐。
errHTML = '''
<HTML><HEAD><TITLE>
Friends CGI Demo</TITLE></HEAD>
<BODY><H3>ERROR</H3>
<B>%s</B><P>
<FORM><INPUT TYPE=button VALUE=Back
ONCLICK="window.history.back()"></FORM>
</BODY></HTML>
'''
cursor.execute('''
CREATE TABLE users (
login VARCHAR(8),
uid INTEGER,
prid INTEGER)
''')
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# f-string
f-string是python3.6之后版本添加的,称之为字面量格式化字符串,是新的格式化字符串的语法。之前一般用百分号:
>>> name = 'Runoob'
>>> 'Hello %s' % name
'Hello Runoob'
2
3
f-string格式化字符串以f开头,后面跟着字符串,字符串中的表达式用大括号{}包起来,它会将变量或表达式计算后的值替换进去,如下:
>>> name = 'Runoob'
>>> f'Hello {name}' # 替换变量
'Hello Runoob'
>>> f'{1 + 2}' # 使用表达式
'3'
>>> w = {'name': 'Runoob', 'url': 'www.runoob.com'}
>>> f'{w["name"]}: {w["url"]}'
'Runoob: www.runoob.com'
2
3
4
5
6
7
8
9
用了这种方式明显更简单了,不用再去判断使用%s,还是%d。在Python3.8的版本中可以使用=符号来拼接运算符表达式与结果:
>>> x = 1
>>> print(f'{x + 1}') # Python 3.6
2
>>> x = 1
>>> print(f'{x + 1 = }')# Python 3.8
x + 1 = 2
2
3
4
5
6
7
# Unicode字符串
在Python2中,普通字符串是以8位ASCII码进行存储的,而Unicode字符串则存储为16位unicode字符串,这样能够表示更多的字符集。使用的语法是在字符串前面加上前缀u。在Python3中,所有的字符串都是Unicode字符串。
# Python 的字符串内建函数
Python的字符串常用内建函数如下:
- capitalize() 将字符串的第一个字符转换为大写
- 描述: 将字符串的第一个字母编程大写,其他字母变小写。
- 语法:
str.capitalize() - 参数: 无
- 返回值: 该方法返回一个首字母大写的字符串
str = 'this is string Example From Runoob ... wow!!!'
print("str.capitalize(): ", str.capitalize())
2

- center(width, fillchar) 返回一个指定的宽度width居中的字符串,fillchar为填充的字符,默认为空格。
- 描述: 返回一个指定的宽度width居中的字符串,fillchar为填充的字符,默认为空格。
- 语法:
str.center(width[, fillchar]) - 参数:
- width: 字符串的总宽度
- fillchar: 填充字符
- 返回值: 返回一个指定的宽度width居中的字符串,如果width小于字符串宽度直接返回字符串,否则使用fillchar去填充
str = "[runoob]"
print("str.center(40, '*'): ", str.center(40, '*'))
2

- count(str, beg=0, end=len(string)) 返回str在string里面出现的次数,如果beg或者end指定则返回指定范围内str出现的次数
- 描述: 用于统计字符串里某个字符出现的次数,可选参数为在字符串搜索的开始与结束位置
- 语法:
str.count(sub, start = 0, end = len(string)) - 参数:
- sub: 搜索的子字符串
- start: 字符串开始搜索的位置,默认为第一个字符,第一个字符索引值为0
- end: 字符串中结束搜索的位置,字符中第一个字符的索引为0,默认为字符串的最后一个位置
- 返回值: 该方法返回子字符串在字符串中出现的次数
str = "www.runoob.com"
sub = 'o'
print("str.count('o'): ", str.count(sub))
sub = 'run'
print("str.count('run', 0, 10): ", str.count(sub, 0, 10))
2
3
4
5
6

- bytes.decode(encoding = "utf-8", errors = "strict") Python3中没有
decode方法,但可以使用bytes对象的decode()方法来解码给定的bytes对象,这个bytes对象可以由str.encode()来编码返回- 描述: 以指定的编码格式解码bytes对象,默认编码为utf-8
- 语法:
bytes.decode(encoding = "utf-8", error = "strict") - 参数:
- encoding: 要使用的编码,如UTF-8
- errors: 设置不同错误的处理方案,默认为strict,意味编码错误引起一个UnicodeError。其他可能的值有ignore, replace, xmlcharrefreplace, backslashreplace, 以及通过
codecs.register_error()注册的任何值。
- 返回值: 返回解码后的字符串
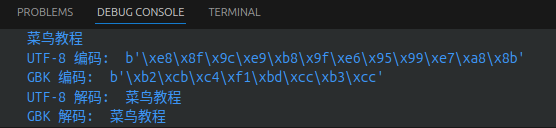
str = "菜鸟教程"
str_utf8 = str.encode("UTF-8")
str_gbk = str.encode("GBK")
print(str)
print("UTF-8 编码: ", str_utf8)
print("GBK 编码: ", str_gbk)
print("UTF-8 解码: ", str_utf8.decode('UTF-8', 'strict'))
print("GBK 解码: ", str_gbk.decode('GBK', 'strict'))
2
3
4
5
6
7
8
9
10
11
- encode(encoding = 'UTF-8', errors = 'strict') 以 encoding 指定的编码格式编码字符串,如果出错默认报一个 ValueError 的异常,除非 errors 指定的是 ignore 或者 replace
- 描述:
- 语法:
- 参数:
- 返回值:
- endswith(suffix, beg = 0, end = len(string)) 检查字符串是否以 suffix 结束,如果 beg 或者 end 指定则检查指定范围内是否以 suffix 结束,如果是,则返回 True,否则返回 False
- 描述:
- 语法:
- 参数:
- 返回值:
- expandtabs(tabsize = 8) 把字符串 string 中的 tab 符合转为空格,tab 符号默认的空格数是 8.
- 描述:
- 语法:
- 参数:
- 返回值:
- find(str, beg = 0, end = len(string)) 检测 str 是否包含在字符串中,如果指定范围 beg 和 end,则检查是否包含在指定范围内,如果包含返回开始的索引值,否则返回-1
- 描述:
- 语法:
- 参数:
- 返回值:
- index(str, beg = 0, end = len(string)) 根find()方法一样,只不过如果str不在字符串中会报一个异常
- 描述:
- 语法:
- 参数:
- 返回值:
- isalnum() 检查字符串是否由字母和数字组成,即字符串中的所有字符都是字母或数字,如果字符串至少有一个字符,并且所有字符都是字母或数字,则返回True,否则返回False
- 描述:
- 语法:
- 参数:
- 返回值:
- isalpha() 如果字符串至少有一个字符并且所有字符都是字母或中文字则返回True,否则返回False
- 描述:
- 语法:
- 参数:
- 返回值:
- isdigit() 如果字符串只包含数字则返回True否则返回False
- 描述:
- 语法:
- 参数:
- 返回值:
- islower() 如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回True,否则返回False
- 描述:
- 语法:
- 参数:
- 返回值:
- isnumeric() 如果字符串中只包含数字字符,则返回True,否则返回False
- 描述:
- 语法:
- 参数:
- 返回值:
- isspace() 如果字符串中只包含空白,则返回True,否则返回False
- 描述:
- 语法:
- 参数:
- 返回值:
- istitle() 如果字符串是标题化的(title),则返回True,否则返回False
- 描述:
- 语法:
- 参数:
- 返回值:
- isupper() 如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回True,否则返回False
- 描述:
- 语法:
- 参数:
- 返回值:
- join(seq) 以指定字符串作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串
- 描述:
- 语法:
- 参数:
- 返回值:
- len(string) 返回字符串长度
- 描述:
- 语法:
- 参数:
- 返回值:
- ljust(width[, fillchar]) 返回一个源字符串左对齐,并使用 fillchar 填充至长度width的新字符串,fillchar 默认为空格。
- 描述:
- 语法:
- 参数:
- 返回值:
- lower() 转换字符串中所有大写字符为小写
- 描述:
- 语法:
- 参数:
- 返回值:
- lstrip() 截掉字符串左边的空格或指定字符
- 描述:
- 语法:
- 参数:
- 返回值:
- maketrans() 创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符串,第二个参数也是字符串表示转换的目标
- 描述:
- 语法:
- 参数:
- 返回值:
- max(str) 返回字符串中最大的字母
- 描述:
- 语法:
- 参数:
- 返回值:
- min(str) 返回字符串中最小的字母
- 描述:
- 语法:
- 参数:
- 返回值:
- replace(old, new[, max]) 将字符串中的 old 替换成 new,如果 max 指定,则替换不超过 max 次
- 描述:
- 语法:
- 参数:
- 返回值:
- rfind(str, beg = 0, end = len(string)) 类似于find()函数,不过是从右边开始查找
- 描述:
- 语法:
- 参数:
- 返回值:
- rindex(str, beg = 0, end = len(string)) 类似于 index(),不过是从右边开始
- 描述:
- 语法:
- 参数:
- 返回值:
- rjust(width[, fillchar]) 返回一个原字符串右对齐,并使用fillchar(默认空格)填充至长度width的新字符串
- 描述:
- 语法:
- 参数:
- 返回值:
- rstrip() 删除字符串末尾的空格或指定字符
- 描述:
- 语法:
- 参数:
- 返回值:
- split(str = "", num = string.count(str)) 以 str 为分隔符截取字符串,如果 num 有指定值,则仅截取 num + 1 个子字符串
- 描述:
- 语法:
- 参数:
- 返回值:
- splitlines([keepends]) 按照行('\r', '\r\n', '\n')分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为False,不包含换行符,如果为True,则保留换行符。
- 描述:
- 语法:
- 参数:
- 返回值:
- startswith(substr, beg = 0, end = len(string)) 检查字符串是否以指定子字符串 substr 开头,是则返回True,否则返回False。如果beg和end指定值,则在指定范围内检查。
- 描述:
- 语法:
- 参数:
- 返回值:
- strip([chars]) 在字符串上执行 lstrip() 和 rstrip()
- 描述:
- 语法:
- 参数:
- 返回值:
- swapcase() 将字符串中大写转换为小写,小写转换为大写
- 描述:
- 语法:
- 参数:
- 返回值:
- title() 返回标题化字符串,就是说所有单词都是以大写开始,其余字母均为小写
- 描述:
- 语法:
- 参数:
- 返回值:
- translate(table, deletechars = "") 根据 table 给出的表(包含256个字符)转换为string的字符,要过滤掉的字符放到deletechars参数中
- 描述:
- 语法:
- 参数:
- 返回值:
- upper() 转换字符串中的小写字母为大写
- 描述:
- 语法:
- 参数:
- 返回值:
- zfill(width) 返回长度为width的字符串,原字符串右对齐,前面填充0
- 描述:
- 语法:
- 参数:
- 返回值:
- isdecimal() 检查字符串是否只包含十进制字符,如果是则返回True,否则返回False
- 描述:
- 语法:
- 参数:
- 返回值:
# Python3 列表
序列是Python中最基本的数据结构,序列中的每个值都有对应的位置值,称之为索引,第一个索引是0,第二个索引是1,依次类推。Python有6个序列的内置类型,最常见的是列表和元组。列表可以进行的操作包括索引,切片,加,乘,检查成员。此外,Python已经内置确定序列的长度以及确定最大和最小的元素的方法。列表是最常用的数据类型,它可以作为一个方括号内的逗号分隔值出现。列表的数据项不需要具有相同的类型。创建一个列表,只要把逗号分隔的不同的数据项使用方括号括起来即可,如下:
list1 = ['Google', 'Runoob', 1997, 2000]
list2 = [1, 2, 3, 4, 5]
list3 = ["a", "b", "c", "d"]
list4 = ['red', 'green', 'blue', 'yellow', 'white', 'black']
2
3
4
# 访问列表中的值
与字符串的索引一样,列表索引从0开始,第二个索引是1,依次类推,通过索引列表可以进行截取、组合等操作。
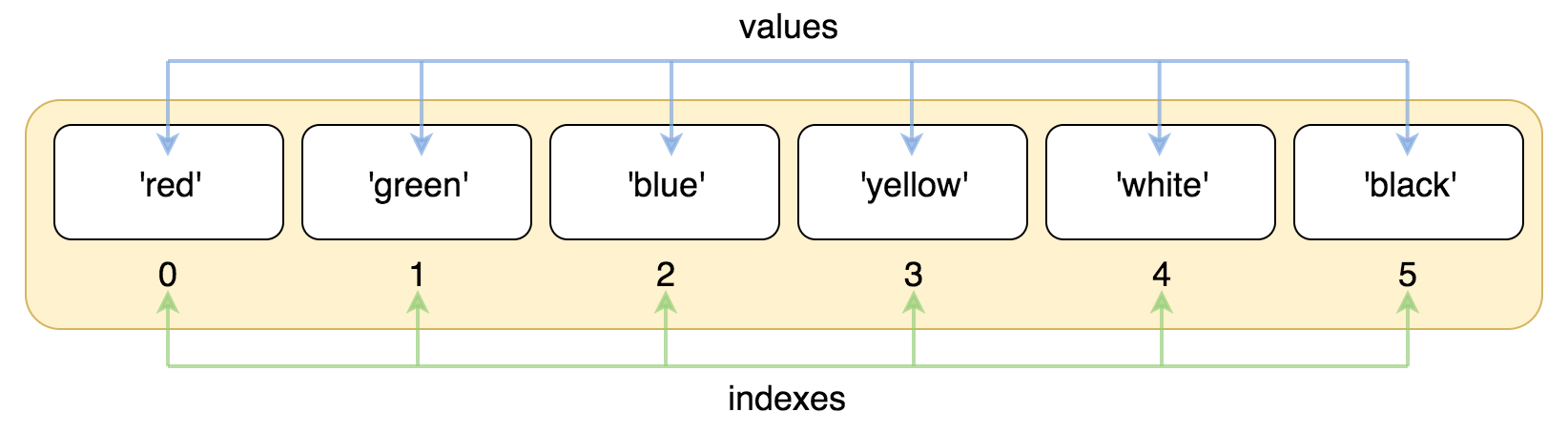
list = ['red', 'green', 'blue', 'yellow', 'white', 'black']
print(list[0])
print(list[1])
print(list[2])
2
3
4
索引也可以从尾部开始,最后一个元素的索引为-1,往前一位为-2,依次类推
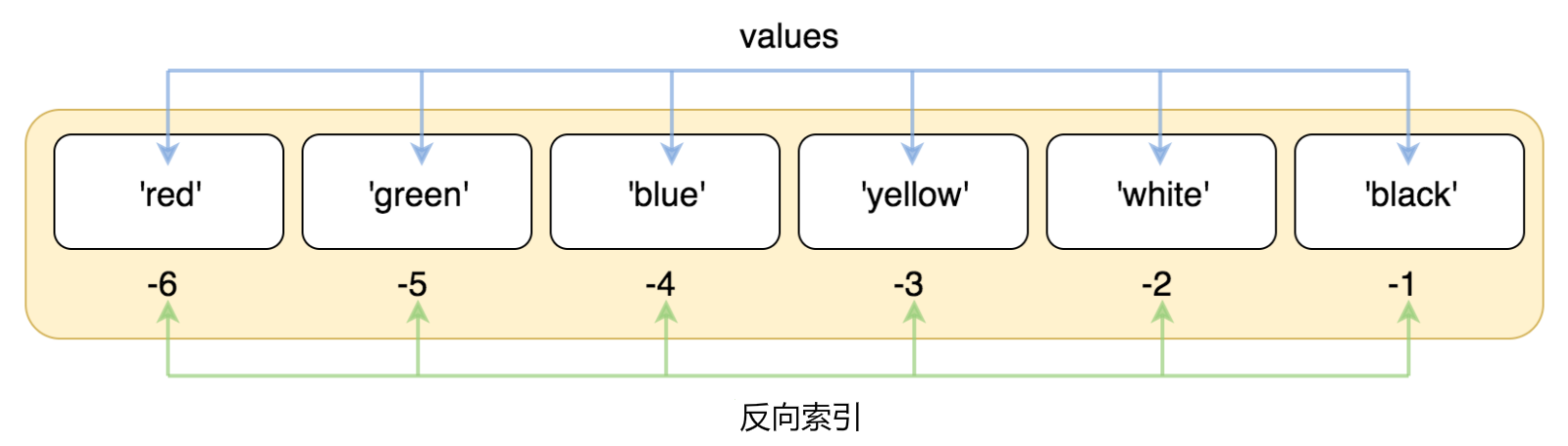
list = ['red', 'green', 'blue', 'yellow', 'white', 'black']
print(list[-1])
print(list[-2])
print(list[-3])
2
3
4
使用下标索引访问列表中的值,还可以使用方括号[]的形式截取字符,如下:
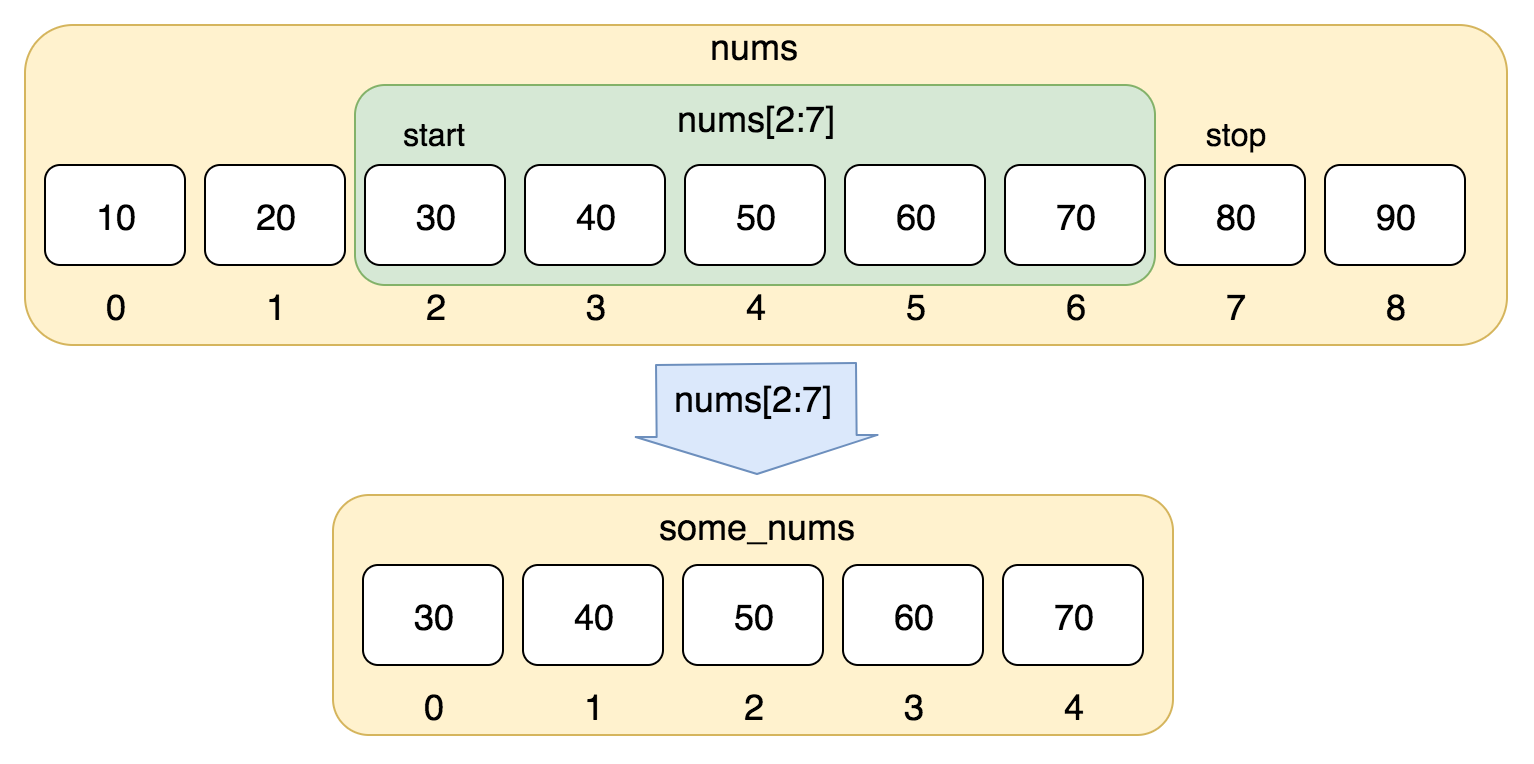
nums = [10, 20, 30, 40, 50, 60, 70, 80, 90]
print(nums[0:4])
2
使用负数索引值截断:
list = ['Google', 'Runoob', "Zhihu", "Taobao", "Wiki"]
# 读取第二位
print("list[1]: ", list[1])
# 从第二位开始(包含)截取到倒数第二位(不包含)
print("list[1:-2]: ", list[1:-2])
2
3
4
5
6
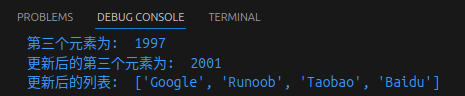
# 更新列表
可以对列表的数据项进行修改或更新,也可以使用append()方法来添加列表项,如下:
list = ['Google', 'Runoob', 1997, 2000]
print("第三个元素为: ", list[2])
list[2] = 2001
print("更新后的第三个元素为: ", list[2])
list1 = ['Google', 'Runoob', 'Taobao']
list1.append('Baidu')
print("更新后的列表: ", list1)
2
3
4
5
6
7
8
9
# 删除列表元素
可以使用 del 语句来删除列表中的元素,如下:
list = ['Google', 'Runoob', 1997, 2000]
print("原始列表: ", list)
del list[2]
print("删除第三个元素: ", list)
2
3
4
5

# Python列表脚本操作符
列表对+和*的操作符与字符串相似,+号用于组合列表,*号用于重复列表。
| Python表达式 | 结果 | 描述 |
|---|---|---|
len([1, 2, 3]) | 3 | 长度 |
[1, 2, 3] + [4, 5, 6] | [1, 2, 3, 4, 5, 6] | 组合 |
['Hi!']*4 | ['Hi!', 'Hi!', 'Hi!', 'Hi!'] | 重复 |
3 in [1, 2, 3] | True | 元素是否在列表中 |
for x in [1, 2, 3]: print(x, end=" ") | 1 2 3 | 迭代 |
# Python列表截取与拼接
Python的列表截取与字符串操作类似,如下:
L = ['Google', 'Runoob', 'Taobao']
| Python表达式 | 结果 | 描述 |
|---|---|---|
L[2] | 'Taobao' | 读取第三个元素 |
L[-2] | 'Runoob' | 从右侧开始读取倒数第二个元素 |
L[1:] | ['Runoob', 'Taobao'] | 输出从第二个元素开始后的所有元素 |
# 嵌套列表
使用嵌套列表即在列表里创建其他列表,例如:
>>> a = ['a', 'b', 'c']
>>> n = [1, 2, 3]
>>> x = [a, n]
>>> x
[['a', 'b', 'c'], [1, 2, 3]]
>>> x[0][1]
'b'
2
3
4
5
6
7
# 列表比较
列表比较需要引入operator模块的eq方法(详见: Python operator模块)
import operator
a = [1, 2]
b = [2, 3]
c = [2, 3]
print("operator.eq(a, b): ", operator.eq(a, b)) # False
print("operator.eq(c, b): ", operator.eq(c, b)) # True
2
3
4
5
6
7
8
# Python列表函数&方法
len(list): 列表元素个数- 描述:
- 语法:
- 参数:
- 返回值:
max(list): 返回列表元素最大值- 描述:
- 语法:
- 参数:
- 返回值:
min(list): 返回列表元素最小值- 描述:
- 语法:
- 参数:
- 返回值:
list(seq): 将元组转换为列表- 描述:
- 语法:
- 参数:
- 返回值:
list.append(obj): 在列表末尾添加新的对象- 描述:
- 语法:
- 参数:
- 返回值:
list.count(obj): 统计某个元素在列表中出现的次数- 描述:
- 语法:
- 参数:
- 返回值:
list.extend(seq): 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表)- 描述:
- 语法:
- 参数:
- 返回值:
list.index(obj): 从列表中找出某个值第一个匹配项的索引位置- 描述:
- 语法:
- 参数:
- 返回值:
list.insert(index, obj): 将对象插入列表- 描述:
- 语法:
- 参数:
- 返回值:
list.pop([index=-1]): 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值- 描述:
- 语法:
- 参数:
- 返回值:
list.remove(obj): 移除列表中某个值的第一个匹配项- 描述:
- 语法:
- 参数:
- 返回值:
list.reverse(): 反向列表中的元素- 描述:
- 语法:
- 参数:
- 返回值:
list.sort(key=None, reverse=False): 对原列表中进行排序- 描述:
- 语法:
- 参数:
- 返回值:
list.clear(): 清空列表- 描述:
- 语法:
- 参数:
- 返回值:
list.copy(): 复制列表- 描述:
- 语法:
- 参数:
- 返回值:
# Python3 元组
Python的元组与列表类似,不同之处在于元组的元素不能修改。元组使用小括号(),列表使用方括号[]。元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可。
>>> tup1 = ('Google', 'Runoob', 1997, 2000)
>>> tup2 = (1, 2, 3, 4, 5)
>>> tup3 = "a", "b", "c", "d" # 不需要括号也可
>>> type(tup3)
<class 'tuple'>
>>> tup4 = () # 创建空元组
2
3
4
5
6
元组中只包含一个元素时,需要在元素后面添加逗号,,否则括号会被当做运算符使用:
>>> tup1 = (50)
>>> type(tup1) # 不加逗号,类型为整型
<class 'int'>
>>> tup1 = (50,)
>>> type(tup1) # 加上逗号,类型为元组
<class 'tuple'>
2
3
4
5
6
7
元组与字符串类似,下标索引从0开始,可以进行截取,组合等。
# 访问元组
元组可以使用下标索引访问元组中的值,如下:
tup1 = ('Google', 'Runoob', 1997, 2000)
tup2 = (1, 2, 3, 4, 5, 6, 7)
print("tup1[0]: ", tup1[0])
print("tup2[1:5]", tup2[1:5])
2
3
4
5
# 修改元组
元组中的元素值是不允许修改的,但可以对元组进行连接组合,如下:
tup1 = (12, 34.56)
tup2 = ('abc', 'xyz')
# 以下修改元组元素操作是非法的
# tup1[0] = 100
# 创建一个新的元组
tup3 = tup1 + tup2
print(tup3)
2
3
4
5
6
7
8
9
# 删除元组
元组中的元素值是不允许删除的,但可以使用del语句来删除整个元组,如下:
tup = ('Google', 'Runoob', 1997, 2000)
print(tup)
del tup
print("删除后的元组 tup : ")
print(tup)
2
3
4
5
6

# 元组运算符
与字符串一样,元组之间可以使用+、+=、和*号进行运算,元组可以组合和复制,运算后会生成一个新的元组。
a = (1, 2, 3) b = (4, 5, 6)
| Python表达式 | 结果 | 描述 |
|---|---|---|
len((1, 2, 3)) | 3 | 计算元素个数 |
c = a + b | (1, 2, 3, 4, 5, 6) | 连接,c就是一个新的元组,它包含了a和b中的所有元素 |
a += b | (1, 2, 3, 4, 5, 6) | 连接,a就变成了一个新的元组,它包含了a和b中的所有元素 |
('Hi!') * 4 | ('Hi!', 'Hi!', 'Hi!', 'Hi!') | 复制 |
3 in (1, 2, 3) | True | 元素是否存在 |
for x in (1, 2, 3): print(x, end=" ") | 1 2 3 | 迭代 |
# 元组索引,截取
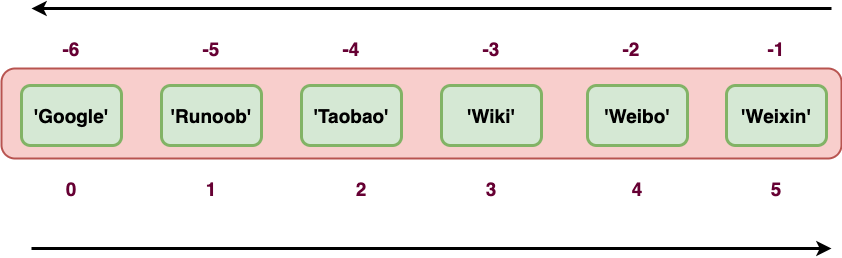
元组也是一个序列,所以可以访问元组中的指定位置的元素,也可以截取索引中的一段元素,如下:
tup = ('Google', 'Runoob', 'Taobao', 'Wiki', 'Weibo','Weixin')
# 元组内置函数
len(tuple): 元组长度- 描述:
- 语法:
- 参数:
- 返回值:
max(tuple): 元组元素最大值- 描述:
- 语法:
- 参数:
- 返回值:
min(tuple): 元组元素最小值- 描述:
- 语法:
- 参数:
- 返回值:
tuple(iterable): 将可迭代序列转换为元组- 描述:
- 语法:
- 参数:
- 返回值:
关于元组是不可变的
所谓元组的不可变指的是元组所指向的内存中的内容不可变。
>>> tup = ('r', 'u', 'n', 'o', 'o', 'b')
>>> tup[0] = 'g' # 不支持修改元素
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
>>> id(tup) # 查看内存地址
4440687904
>>> tup = (1, 2, 3)
>>> id(tup)
4441088800 # 内存地址不一样了
2
3
4
5
6
7
8
9
10
从以上实例可以看出,重新赋值的元组tup,绑定到新的对象了,不是修改了原来的对象。
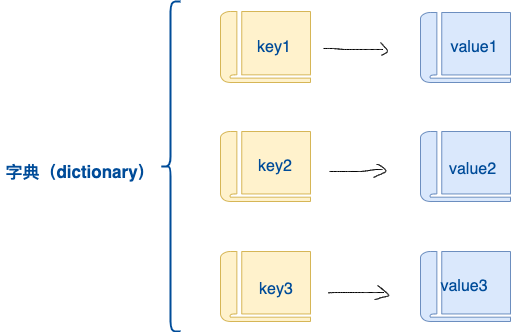
# Python3 字典
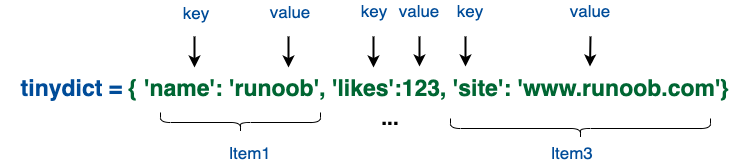
字典是另一种可变容器模型,且可存储任意类型对象。字典的每个键值key->value对用:分隔,每个键值对之间用逗号(,)分隔,整个字典包括在花括号{}中,格式如下:
d = {key1: value1, key2: value2, key3: value3}
注意
dict作为Python的关键字和内置函数,变量名不建议命名为dict
键必须是唯一的,但值则不必,值可以取任何数据类型,但键必须是不可变的,如字符串,数字。
# 创建空字典
使用大括号{}创建空字典
# 使用大括号 {} 创建空字典:
emptyDict = {}
# 打印字典
print(emptyDict)
# 查看字典的数量
print("Length:", len(emptyDict))
# 查看类型
print(type(emptyDict))
2
3
4
5
6
7
8
9
10
11
使用内建函数dict()创建字典:
emptyDict = dict()
# 打印字典
print(emptyDict)
# 查看字典的数量
print("Length:", len(emptyDict))
# 查看类型
print(type(emptyDict))
2
3
4
5
6
7
8
9
10
# 访问字典里的值
把相应的键放入到方括号中,如下:
tinydict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'}
print("tinydict['Name']:", tinydict['Name'])
print("tinydict['Age']:", tinydict['Age'])
2
3
4
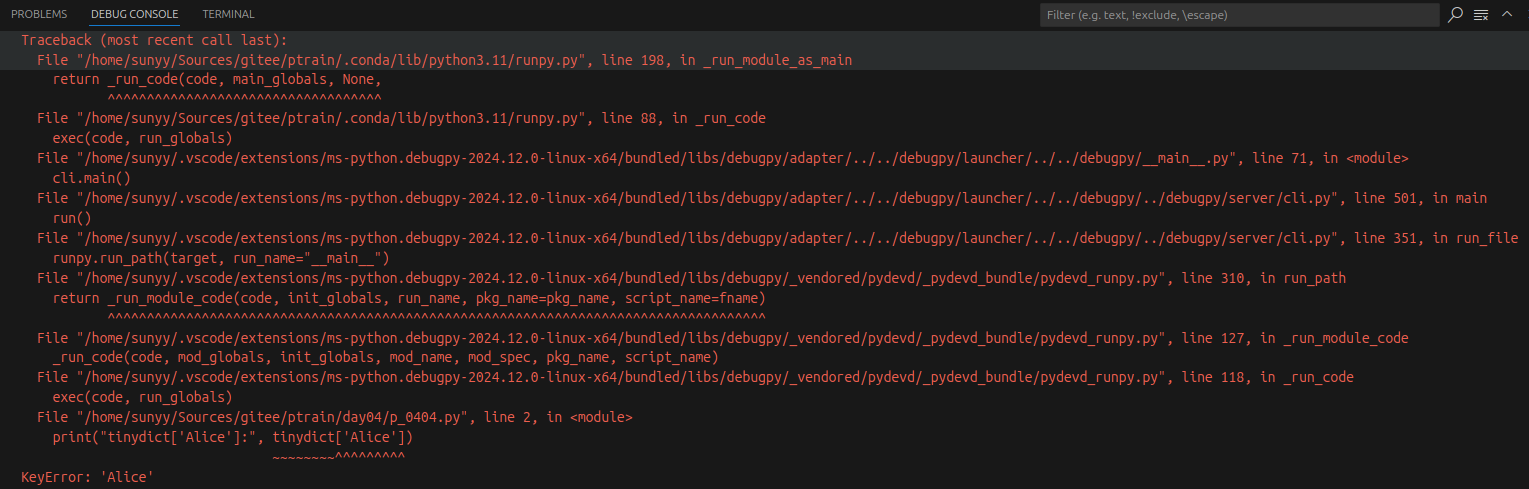
如果用字典里没有的键访问数据,会输出错误:
tinydict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'}
print("tinydict['Alice']:", tinydict['Alice'])
2
# 修改字典
向字典添加新内容的方法是增加新的键值对,修改或删除已有键值对如下:
tinydict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'}
tinydict['Age'] = 8 # 更新 Age
tinydict['School'] = "菜鸟教程" # 添加信息
print("tinydict['Age']: ", tinydict['Age'])
print("tinydict['School']: ", tinydict['School'])
2
3
4
5
6
7
# 删除字典元素
能删单一的元素也能清空字典,清空只需一项操作。显示删除一个字典用del命令, 如下:
tinydict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'}
del tinydict['Name'] # 删除键 'Name'
tinydict.clear() # 清空字典
del tinydict # 删除字典
print("tinydict['Age']: ", tinydict['Age'])
print("tinydict['School']: ", tinydict['School'])
2
3
4
5
6
7
8
但这会引发一个异常,因为执行del操作后字典不再存在:
:::info 字典键的特性 字典值可以是任何的python对象,既可以是标准的对象,也可以是用户定义的,但键不行。
- 不允许同一个键出现两次,创建时如果同一个键被赋值两次,后一个值会覆盖前一个值,如下:
tinydict = {'Name': 'Runoob', 'Age': 7, 'Name': '小菜鸟'}
print("tinydict['Name']: ", tinydict['Name'])
2
- 键必须是不可变的,所以可以用数字,字符串或元组充当,但用列表就不行,如下:
tinydict = {['Name']: 'Runoob', 'Age', 7}
print("tinydict['Name']: ", tinydict['Name'])
2
:::
# 字典内置函数&方法
len(dict): 计算字典元素个数,即键的总数- 描述:
- 语法:
- 参数:
- 返回值:
str(dict): 输出字典,可以打印的字符串表示- 描述:
- 语法:
- 参数:
- 返回值:
type(variable): 返回输入的变量类型,如果变量是字典就返回字典类型- 描述:
- 语法:
- 参数:
- 返回值:
dict.clear(): 删除字典内所有元素- 描述:
- 语法:
- 参数:
- 返回值:
dict.copy(): 返回一个字典的浅复制- 描述:
- 语法:
- 参数:
- 返回值:
dict.fromkeys(): 创建一个新字典,以序列seq中元素做字典的键,val为字典所有键对应的初始值- 描述:
- 语法:
- 参数:
- 返回值:
dict.get(key, default=None): 返回指定键的值,如果键不在字典中返回default设置的默认值- 描述:
- 语法:
- 参数:
- 返回值:
key in dict: 如果键在字典dict里返回True,否则返回False- 描述:
- 语法:
- 参数:
- 返回值:
dict.items(): 以列表返回一个视图对象- 描述:
- 语法:
- 参数:
- 返回值:
dict.keys(): 返回一个视图对象- 描述:
- 语法:
- 参数:
- 返回值:
dict.setdefault(key, default=None): 和get()类似,但如果键不存在与字典中,将会添加键并将值设置为default- 描述:
- 语法:
- 参数:
- 返回值:
dict.update(dict2): 把字典dict2的键值对更新到dict里- 描述:
- 语法:
- 参数:
- 返回值:
dict.values(): 返回一个视图对象- 描述:
- 语法:
- 参数:
- 返回值:
pop(key[,default]): 删除字典key(键)所对应的值,返回被删除的值- 描述:
- 语法:
- 参数:
- 返回值:
popitem(): 返回并删除字典中的最后一对键和值- 描述:
- 语法:
- 参数:
- 返回值:
# Python3 集合
集合(set)是一个无序的不重复元素序列。集合中的元素不会重复,并且可以进行交集、并集、差集等常见的集合操作。可以使用大括号{}创建集合,元素之间用逗号,分隔,或者也可以使用set()函数创建集合。
创建格式:
parame = {value01, value02, ...}
# 或者
set(value)
2
3
以下是一个简单实例:
set1 = {1, 2, 3, 4} # 直接使用大括号创建集合
set2 = set([4, 5, 6, 7]) # 使用 set() 函数从列表创建集合
2
注意
创建一个空集合必须用set()而不是{},因为{}是用来创建一个空字典。
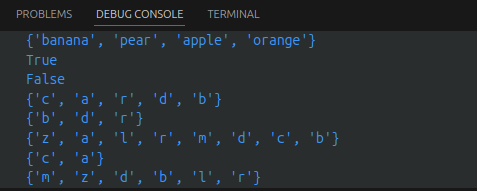
basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
print(basket) # 这里演示的是去重功能
print('orange' in basket) # 快速判断元素是否在集合内
print('crabgrass' in basket)
# 下面展示两个集合间的运算
a = set('abracadabra')
b = set('alacazam')
print(a)
print(a - b) # a中包含而b中不包含的元素
print(a | b) # a或b中包含的所有元素
print(a & b) # a和b中都包含的元素
print(a ^ b) # 不同时包含于a和b的元素
y = {x for x in 'abracadabra' if x not in 'abc'} # 集合推导式 {'r', 'd'}
print(y)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 集合的基本操作
- 添加元素:
s.add(x)还有一个方法,也可以添加元素,且参数可以是列表,元组,字典等s.update(x)
thisset = set(("Google", "Runoob", "Taobao"))
thisset.add("Facebook")
print(thisset)
thisset.update({1, 3})
print(thisset)
thisset.update([1, 4], [5, 6])
print(thisset)
2
3
4
5
6
7

- 移除元素:
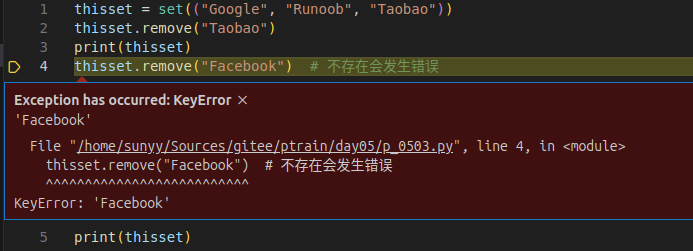
s.remove(x)将元素x从集合s中移除,如果元素不存在,则会发生错误。
thisset = set(("Google", "Runoob", "Taobao"))
thisset.remove("Taobao")
print(thisset)
# thisset.remove("Facebook") # 不存在会发生错误
print(thisset)
2
3
4
5

还有一个方法也是移除集合中的元素,如果元素不存在,不会发生错误,格式: s.discard(x)
thisset.discard("Facebook")
print(thisset)
2
也可以设置随机删除集合中的一个元素,格式: s.pop()
thisset = set(("Google", "Runoob", "Taobao"))
x = thisset.pop()
print(thisset)
print(x)
2
3
4


多次执行测试结果都不一样,set集合的pop方法会对集合进行无序的排列,然后将这个无序排列集合的左面第一个元素进行删除。
- 计算集合元素个数:
len(s) - 清空集合:
s.clear() - 判断元素是否在集合中存在:
x in s
# 集合内置方法完整列表
add(): 为集合添加元素- 描述:
- 语法:
- 参数:
- 返回值:
clear(): 移除集合中的所有元素- 描述:
- 语法:
- 参数:
- 返回值:
copy(): 拷贝一个集合- 描述:
- 语法:
- 参数:
- 返回值:
difference(): 返回多个集合的差集- 描述:
- 语法:
- 参数:
- 返回值:
difference_update(): 移除集合中的元素,该元素在指定的集合也存在- 描述:
- 语法:
- 参数:
- 返回值:
discard(): 删除集合中指定的元素- 描述:
- 语法:
- 参数:
- 返回值:
intersection(): 返回集合的交集,返回一个新集合- 描述:
- 语法:
- 参数:
- 返回值:
intersection_update(): 返回集合的交集,并在元素的集合上移除不重叠的元素- 描述:
- 语法:
- 参数:
- 返回值:
isdisjoint(): 判断两个集合是否包含相同的元素,如果没有返回True,否则返回False- 描述:
- 语法:
- 参数:
- 返回值:
issubset(): 判断指定集合是否为该方法参数集合的子集- 描述:
- 语法:
- 参数:
- 返回值:
issuperset(): 判断该方法的参数集合是否为指定集合的子集- 描述:
- 语法:
- 参数:
- 返回值:
pop(): 随机移除元素- 描述:
- 语法:
- 参数:
- 返回值:
remove(): 移除指定元素- 描述:
- 语法:
- 参数:
- 返回值:
symmetric_difference(): 返回两个集合中不重复的元素集合- 描述:
- 语法:
- 参数:
- 返回值:
symmetric_difference_update(): 移除当前集合中在另外一个指定集合相同的元素,并将另外一个指定集合中不同的元素插入到当前集合中。- 描述:
- 语法:
- 参数:
- 返回值:
union(): 返回两个集合的并集- 描述:
- 语法:
- 参数:
- 返回值:
update(): 给集合添加元素- 描述:
- 语法:
- 参数:
- 返回值:
len(): 计算集合元素个数- 描述:
- 语法:
- 参数:
- 返回值:
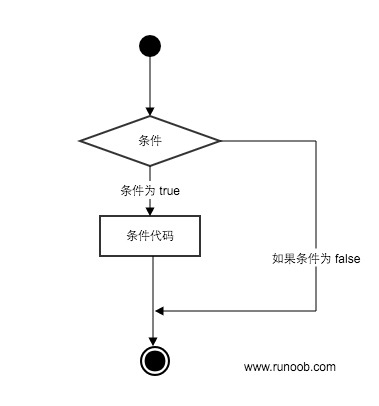
# Python3 条件控制
Python条件语句是通过一条或多条语句的执行结果(True或者False)来决定执行的代码块。

# if 语句
if condition_1:
statement_block_1
elif condition_2:
statement_block_2
else:
statement_block_3
2
3
4
5
6
注意
- 每个条件后面要使用冒号
:,表示接下来是满足条件后要执行的语句块。 - 使用缩进来划分语句块,相同缩进数的语句在一起组成一个语句块。
- 在Python中没有
switch...case语句,但在Python3.10版本添加了match...case,功能类似。

var1 = 100
if var1:
print("1 - if 表达式条件为 True")
print(var1)
var2 = 0
if var2:
print("2 - if 表达式条件为 True")
print(var2)
print("Good bye!")
2
3
4
5
6
7
8
9
10
11
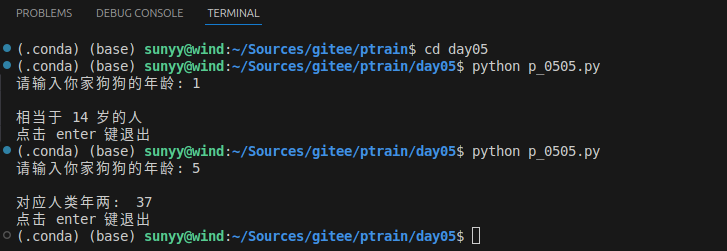
age = int(input("请输入你家狗狗的年龄: "))
print("")
if age <= 0:
print("你是在逗我吧!")
elif age == 1:
print("相当于 14 岁的人")
elif age == 2:
print("相当于 22 岁的人")
elif age > 2:
human = 22 + (age - 2) * 5
print("对应人类年两: ", human)
### 退出提示
input("点击 enter 键退出")
2
3
4
5
6
7
8
9
10
11
12
13
14
| 操作符 | 描述 |
|---|---|
< | 小于 |
<= | 小于等于 |
> | 大于 |
>= | 大于等于 |
== | 等于,比较两个值是否相等 |
!= | 不等于 |
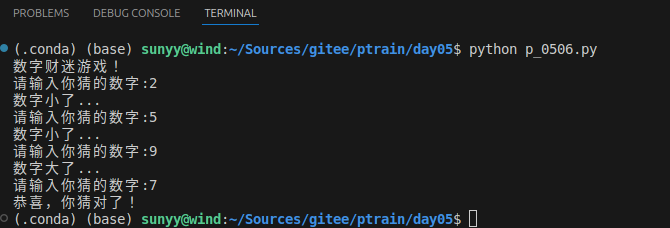
number = 7
guess = -1
print("数字财迷游戏!")
while guess != number:
guess = int(input("请输入你猜的数字:"))
if guess == number:
print("恭喜,你猜对了!")
elif guess < number:
print("数字小了...")
elif guess > number:
print("数字大了...")
2
3
4
5
6
7
8
9
10
11
12
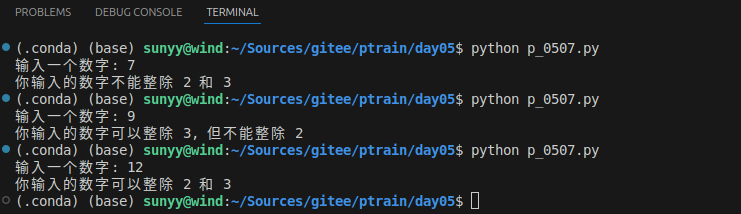
# if 嵌套
num = int(input("输入一个数字: "))
if num % 2 == 0:
if num % 3 == 0:
print("你输入的数字可以整除 2 和 3")
else:
print("你输入的数字可以整除 2, 但不能整除 3")
else:
if num % 3 == 0:
print("你输入的数字可以整除 3, 但不能整除 2")
else:
print("你输入的数字不能整除 2 和 3")
2
3
4
5
6
7
8
9
10
11
# match...case
Python3.10增加了match...case的条件判断,不需要再使用一连串的if-else来判断了。match后的对象会依次与case后的内容进行匹配,如果匹配成功,则执行匹配到的表达式,否则直接跳过,_可以匹配一切。
match subject:
case <pattern_1>:
<action_1>
case <pattern_2>:
<action_2>
case <pattern_3>:
<action_3>
case _:
<action_wildcard>
2
3
4
5
6
7
8
9
case _:类似于C和Java中的default:,当其他case都无法匹配时,匹配这条,保证永远会匹配成功
def http_error(status):
match status:
case 400:
return "Bad request"
case 404:
return "Not found"
case 418:
return "I'm a teapot"
case _:
return "Something's wrong with the internet"
mystatus=400
print(http_error(400))
2
3
4
5
6
7
8
9
10
11
12
13
一个case也可以设置多个匹配条件,条件使用|隔开,例如:
case 401|403|404:
return "Not allowed"
2
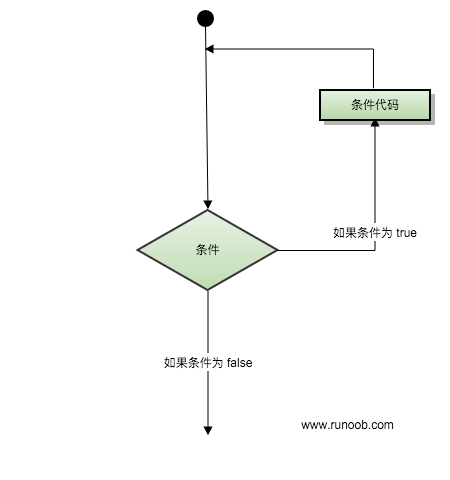
# Python3 循环语句
Python中的循环语句有 for 和 while
Python循环语句的控制结构图如下所示:
# while 循环
while 判断条件(condition):
执行语句(statements)……
2
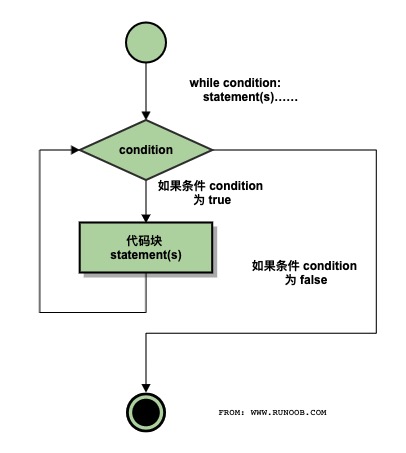

同样需要注意冒号和缩进,另外,在Python中没有do...while循环。
n = 100
sum = 0
counter = 1
while counter <= n:
sum = sum + counter
counter += 1
print("1 到 %d 之和为: %d" % (n, sum))
2
3
4
5
6
7
8
9

无限循环:
#!/usr/bin/python3
var = 1
while var == 1 : # 表达式永远为 true
num = int(input("输入一个数字 :"))
print ("你输入的数字是: ", num)
print ("Good bye!")
2
3
4
5
6
7
8
while循环使用else语句: 如果while后面的条件语句为False时,则执行else的语句块。
while <expr>:
<statement(s)>
else:
<additional_statement(s)>
2
3
4
expr条件语句为True则执行statement(s)语句块,如果为False,则执行additional_statement(s)
#!/usr/bin/python3
count = 0
while count < 5:
print (count, " 小于 5")
count = count + 1
else:
print (count, " 大于或等于 5")
2
3
4
5
6
7
8
简单语句组: 类似if语句的语法,如果while循环体中只有一条语句,可以将该语句与while写在同一行中,如下:
#!/usr/bin/python
flag = 1
while (flag): print ('欢迎访问菜鸟教程!') # 无限循环
print ("Good bye!")
2
3
4
5
6
7
# for 语句
Python for 循环可以遍历任何可迭代对象,如一个列表或者一个字符串。
for <variable> in <sequence>:
<statements>
else:
<statements>
2
3
4
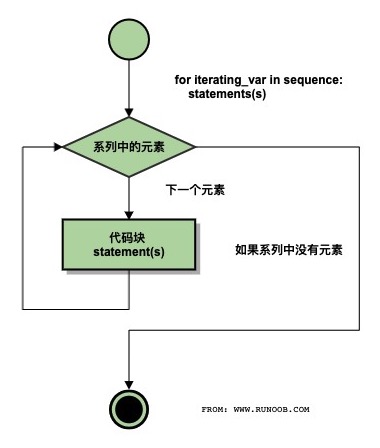
#!/usr/bin/python3
sites = ["Baidu", "Google","Runoob","Taobao"]
for site in sites:
print(site)
2
3
4
5
#!/usr/bin/python3
word = 'runoob'
for letter in word:
print(letter)
2
3
4
5
6
整数范围值可以配合range()函数使用:
#!/usr/bin/python3
# 1 到 5 的所有数字:
for number in range(1, 6):
print(number)
2
3
4
5
for...else: 在Python中,for...else语句用于循环结束后执行一段代码
for item in iterable:
# 循环主体
else:
# 循环结束后执行的代码
2
3
4
for x in range(6):
print(x)
else:
print("Finally finished!")
2
3
4
以下for实例中使用了break语句,break语句用于跳出当前循环体,不会执行else语句:
#!/usr/bin/python3
sites = ["Baidu", "Google","Runoob","Taobao"]
for site in sites:
if site == "Runoob":
print("菜鸟教程!")
break
print("循环数据 " + site)
else:
print("没有循环数据!")
print("完成循环!")
2
3
4
5
6
7
8
9
10
11
# range() 函数
如果需要遍历数字序列,可以使用内置range()函数,它会生成数列,例如:
for i in range(5):
print(i)
2
也可以使用range()指定区间的值:
for i in range(5, 9):
print(i)
2
也可以使range()以指定数字开始并指定不同的增量(甚可以是负数,有时也叫做步长)
for i in range(0, 10, 3):
print(i)
2
负数:
for i in range(-10, -100, -30):
print(i)
2
可以结合range()和len()函数以遍历一个序列的索引,如下:
a = ['Google', 'Baidu', 'Runoob', 'Taobao', 'QQ']
for i in range(len(a)):
print(i, a[i])
2
3
可以使用range()函数创建一个列表:
list(range(5))
# break 和 continue 语句及循环中的 else 子句
break执行流程:
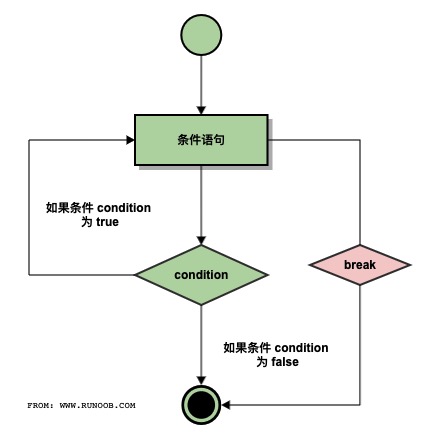
continue执行流程:
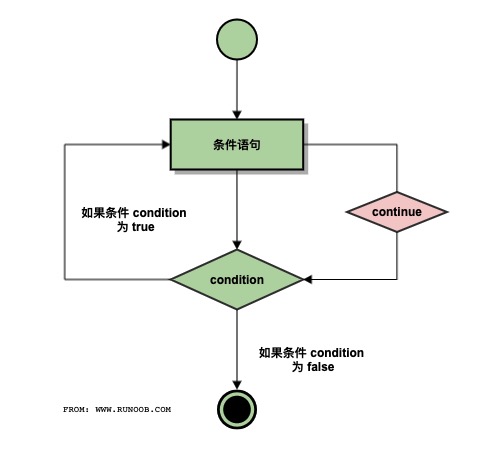


break语句可以跳出for和while的循环体,如果从for或while循环中终止,任何对应的循环else块将不执行
continue语句用来告诉Python跳过当前块中的剩余语句,然后继续进行下一轮循环。
n = 5
while n > 0:
n -= 1
if n == 2:
break
print(n)
print('循环结束。')
2
3
4
5
6
7
n = 5
while n > 0:
n -= 1
if n == 2:
continue
print(n)
print('循环结束。')
2
3
4
5
6
7
#!/usr/bin/python3
for letter in 'Runoob': # 第一个实例
if letter == 'b':
break
print ('当前字母为 :', letter)
var = 10 # 第二个实例
while var > 0:
print ('当前变量值为 :', var)
var = var -1
if var == 5:
break
print ("Good bye!")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
#!/usr/bin/python3
for letter in 'Runoob': # 第一个实例
if letter == 'o': # 字母为 o 时跳过输出
continue
print ('当前字母 :', letter)
var = 10 # 第二个实例
while var > 0:
var = var -1
if var == 5: # 变量为 5 时跳过输出
continue
print ('当前变量值 :', var)
print ("Good bye!")
2
3
4
5
6
7
8
9
10
11
12
13
14
#!/usr/bin/python3
for n in range(2, 10):
for x in range(2, n):
if n % x == 0:
print(n, '等于', x, '*', n//x)
break
else:
# 循环中没有找到元素
print(n, ' 是质数')
2
3
4
5
6
7
8
9
10
# pass 语句
Python pass是空语句,是为了保持程序结构的完整性。pass不做任何事情,一般用作占位语句,如下:
while True:
pass # 等待键盘中断(Ctrl + C)
2
以下示例在字母为o时,执行pass语句块:
#!/usr/bin/python3
for letter in 'Runoob':
if letter == 'o':
pass
print ('执行 pass 块')
print ('当前字母 :', letter)
print ("Good bye!")
2
3
4
5
6
7
8
9
# Python3 编程第一步
# Fibonacci series: 斐波那契数列
# 两个元素的总和确定下一个数
a, b = 0, 1
while b < 10:
print(b)
a, b = b, a + b
2
3
4
5
6

其中,代码a, b = b, a + b的计算方式为先计算右边表达式,然后同时赋值给左边,等价于:
n = b
m = a + b
a = n
b = m
2
3
4
这个例子介绍了一个复合赋值: 变量 a 和 b同时得到新值 0 和 1,最后一行再次使用了同样的方法,可以看到,右边的表达式会在赋值变动之前执行。右边表达式的执行顺序是从左往右的。也可以使用 for 循环实现:
n = 10
a, b = 0, 1
for i in range(n):
print(b)
a, b = b, a + b
2
3
4
5
end关键字: 关键字end可以用于将结果输出到同一行,或者在输出的末尾添加不同的字符,实例如下:
# Fiboanacci series: 斐波那契数列
# 两个元素的总和确定了下一个数
a, b = 0, 1
while b < 1000:
print(b, end=', ')
a, b = b, a + b
2
3
4
5
6

# Python3 推导式
Python推导式是一种独特的数据处理方式,可以从一个数据序列构建另一个新的数据序列的结构体。Python推导式是一种强大且简洁的语法,适用于生成列表、字典、集合和生成器。在适用推导式时,需要注意可读性,尽量保持表达式简洁,以免影响代码的可读性和维护性。
Python支持各种数据结构的推导式:
- 列表(list)推导式
- 字典(dict)推导式
- 集合(set)推导式
- 元组(tuple)推导式
# 列表推导式
列表推导式格式为:
[表达式 for 变量 in 列表]
[out_exp_res for out_exp in input_list]
# 或
[表达式 for 变量 in 列表 if 条件]
[out_exp_res for out_exp in input_list if condition]
2
3
4
5
6
7
out_exp_res: 列表生成元素表达式,可以是有返回值的函数。for out_exp in input_list: 迭代input_list将out_exp传入到out_exp_res表达式中if condition: 条件语句,可以过滤列表中不符合条件的值。
过滤掉长度小于或等于3的字符串列表,并将剩下的转换成大写字母:
names = ['Bob', 'Tom', 'alice', 'Jerry', 'Wendy', 'Smith']
new_names = [name.upper() for name in names if len(name) > 3]
print(new_names)
2
3

计算30以内可以被3整除的整数:
multiples = [i for i in range(30) if i % 3 == 0]
print(multiples)
2

# 字典推导式
字典推到基本格式:
{ key_expr: value_expr for value in collection }
# 或
{ key_expr: value_expr for value in collection if condition }
2
3
4
5
使用字符串及其长度创建字典:
listdemo = ['Google', 'Runoob', 'Taobao']
# 将列表中各字符串值为键,各字符串的长度为值,组成键值对
newdict = {key: len(key) for key in listdemo}
print(newdict)
2
3
4

提供三个数字,以三个数字为键,三个数字的平方为值来创建字典:
dic = {x: x**2 for x in (2, 4, 6)}
print(dic)
2

# 集合推导式
集合推导式基本格式为:
{ expression for item in Sequence }
# 或
{ expression for item in Sequence if conditional }
2
3
4
5
计算数值1, 2, 3的平方数:
setnew = {i**2 for i in (1, 2, 3)}
print(setnew)
2

判断不是abc的字母并输出:
a = {x for x in 'abracadabra' if x not in 'abc'}
print(a)
2

# 元组推导式
元组推导式可以利用range区间、元组、列表、字典和集合等数据类型,快速生成一个满足指定需求的元组。
(expression for item in Sequence)
# 或
(expression for item in Sequence if conditional)
2
3
4
5
元组推导式和列表推导式的用法也完全相同,只是元组推导式用()括起来,而列表推导式为[],另外需要注意的是元组推导式返回的结果是一个生成器对象。
例如,可以使用下面的代码生成一个包含数字1~9的元组:
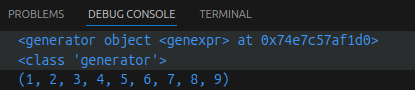
a = (x for x in range(1, 10))
print(a)
print(type(a))
b = tuple(a) # 使用tuple()函数,可以直接将生成器对象转换成元组
print(b)
2
3
4
5
# Python3 迭代器与生成器
# 迭代器
迭代是Python最强大的功能之一,是访问集合元素的一种方式。迭代器是一个可以记住遍历的位置的对象。迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器智能往前不能后退。迭代器有两个基本的方法: iter()和next()。
字符串,列表或元组对象都可用于创建迭代器:
list = [1, 2, 3, 4]
it = iter(list) # 创建迭代器对象
print(next(it)) # 输出迭代器的下一个元素
print(next(it))
2
3
4

迭代器对象可以使用常规for语句进行遍历:
list = [1, 2, 3, 4]
it = iter(list) # 创建迭代器对象
for x in it:
print(x, end=" ")
2
3
4
也可以使用next()函数:
import sys # 引入 sys 模块
list = [1, 2, 3, 4]
it = iter(list) # 创建迭代器对象
while True:
try:
print(next(it))
except StopIteration:
sys.exit()
2
3
4
5
6
7
8
9
10

# 创建一个迭代器
把一个类作为一个迭代器使用需要在类中实现两个方法__iter__()与__next__()。 如果已经了解面向对象编程,就知道类都有一个构造函数,Python的构造函数为__init__(),它会在对象初始化的时候执行。
__iter__()方法返回一个特殊的迭代器对象,这个迭代器对象实现了__next__()方法并通过StopIteration异常标识迭代的完成。
__next__()方法会返回下一个迭代器对象。
创建一个返回数字的迭代器,初始值为 1, 逐步递增 1:
class MyNumbers:
def __iter__(self):
self.a = 1
return self
def __next__(self):
x = self.a
self.a += 1
return x
myclass = MyNumbers()
myiter = iter(myclass)
print(next(myiter))
print(next(myiter))
print(next(myiter))
print(next(myiter))
print(next(myiter))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18

# StopIteration
StopIteration异常用于标识迭代的完成,防止出现无限循环的情况,在__next__()方法中可以设置在完成指定循环次数后触发StopIteration异常来结束迭代。
在20次迭代后停止执行:
class MyNumbers:
def __iter__(self):
self.a = 1
return self
def __next__(self):
if self.a <= 20:
x = self.a
self.a += 1
return x
else:
raise StopIteration
myclass = MyNumbers()
myiter = iter(myclass)
for x in myiter:
print(x)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18

# 生成器
在Python中,使用了yield的函数被称为生成器(generator)。yield是一个关键字,用于定义生成器函数,生成器函数是一种特殊的函数,可以在迭代过程中逐步产生值,而不是一次性返回所有结果。跟普通函数不同的是,生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点理解生成器就是一个迭代器。当在生成器函数中使用yield语句时,函数的执行将会暂停,并将yield后面的表达式作为当前迭代的值返回。然后,每次调用生成器的next()方法或使用for循环进行迭代时,函数会从上次暂停的地方继续执行,直到再次遇到yield语句。这样,生成器函数可以逐步产生值,而不需要一次性计算并返回所有结果。
调用一个生成器函数,返回的是一个迭代器对象。
def countdown(n):
while n > 0:
yield n
n -= 1
# 创建生成器对象
generator = countdown(5)
# 通过迭代生成器获取值
print(next(generator)) # 输出: 5
print(next(generator)) # 输出: 4
print(next(generator)) # 输出: 3
# 使用 for 循环迭代生成器
for value in generator:
print(value) # 输出 2 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16

以上实例,countdown函数是一个生成器函数。它使用yield语句逐步产生从n到1的倒数数字。在每次调用yield语句时,函数会返回当前的倒数值,并在下一次调用时从上次暂停的地方继续执行。通过创建生成器对象并使用next()函数或for循环迭代生成器,可以逐步获取生成器函数产生的值。在上面的例子中,首先使用next()函数获取前三个倒数值,然后通过for循环获取剩下的两个倒数值。生成器函数的优势是它们可以按需生成值,避免一次性生成大量数据并占用大量内存。此外,生成器还可以与其他迭代工具(如for循环)无缝配合使用,提供简洁和高效的迭代方式。
以下实例使用yield实现斐波那契数列:
import sys
def fibonacci(n): # 生成器函数 - 斐波那契数列
a, b, counter = 0, 1, 0
while True:
if (counter > n):
return
yield a
a, b = b, a + b
counter += 1
f = fibonacci(10) # f 是一个迭代器,由生成器返回生成
while True:
try:
print(next(f), end=" ")
except StopIteration:
sys.exit()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18

# Python3 函数
函数是组织号的,可重复利用的,用来实现单一,或相关联功能的代码段。函数能提高应用的模块性,和代码的重复利用率。Python提供了许多内建函数,比如print(),也可以自己创建函数,叫做用户自定义函数。
# 定义一个函数
规则:
- 函数代码块以
def关键词开头,后接函数标识符名称和圆括号() - 任何传入参数和自变量必须放在圆括号中间,圆括号之间可以用于定义参数
- 函数的第一行语句可以选择性地使用文档字符串--用于存放函数说明
- 函数内容以冒号
:起始,并且缩进 return [表达式]结束函数,选择性地返回一个值给调用方,不带表达式的return相当于返回None
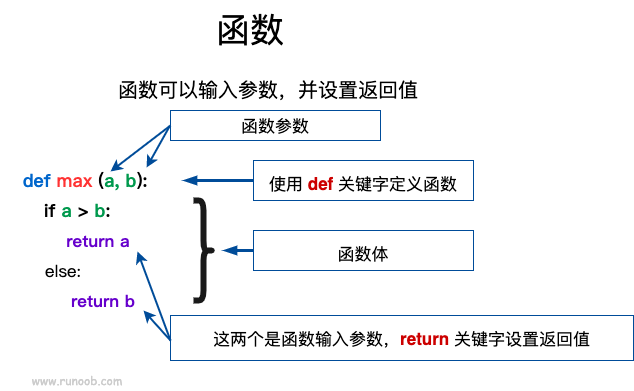
语法:
def 函数名(参数列表):
函数体
2
默认情况下,参数值和参数名称是按函数声明中定义的顺序匹配起来的。
实例:
def hello():
print("Hello World!")
hello()
2
3
4
def max(a, b):
if a > b:
return a
else:
return b
a = 4
b = 5
print(max(a, b))
2
3
4
5
6
7
8
9
def area(width, height):
return width * height
def print_welcome(name):
print("Welcome", name)
print_welcome("Runoob")
w = 4
h = 5
print("width = ", w, " height = ", h, " area = ", area(w, h))
2
3
4
5
6
7
8
9
10
# 函数调用
定义了一个函数: 给了函数一个名称,指定了函数里包含的参数,和代码块结构。这个函数的基本结构完成以后,可以通过另一个函数调用执行,也可以直接从Python命令提示符执行。
# 定义函数
def printme(str):
# 打印任何传入的字符串
print(str)
return
# 调用函数
printme("我要调用用户自定义函数!")
printme("再次调用同一函数")
2
3
4
5
6
7
8
9
# 参数传递
在Python中,类型属于对象,对象有不同类型的区分,变量是没有类型的:
a = [1, 2, 3]
a = "Runoob"
2
以上代码中,[1, 2, 3]是List类型,"Runoob"是String类型,而变量a是没有类型,它仅仅是一个对象的引用(一个指针),可以是指向List类型对象,也可以是指向String类型对象。
可更改(mutable)与不可更改(immutable)对象: 在Python中,strings, tuples和numbers是不可更改的对象,而list, dict等则是可以修改的对象。
- 不可变对象: 变量赋值
a = 5后再赋值a = 10,这里实际是新生成一个int值对象10,再让a指向它,而5被丢弃,不是改变a的值,相当于新生成了a - 可变类型: 变量赋值
la = [1, 2, 3, 4]后再赋值la[2] = 5则是将list la的第三个元素值更改,本身la没有动,只是其内部的一部分值被修改了。
Python函数的参数传递:
- 不可变类型: 类似C++的值传递,如整数、字符串、元组。如
fun(a),传递的只是a的值,没有影响a对象本身。如果在fun(a)内部修改a的值,则是新生成一个a的对象。 - 可变类型: 类似C++的引用传递,如列表,字典。如
fun(la),则是将la真正的传过去,修改后fun外部的la也会受影响。
Python中一切都是对象,严格意义不能说值传递还是引用传递,应该说传不可变对象和传可变对象。
def change(a):
print(id(a)) # 指向的是同一个对象
a = 10
print(id(a)) # 一个新对象
a = 1
print(id(a))
change(a)
2
3
4
5
6
7
8

在函数内部修改形参后,形参指向的是不同的id。
传可变对象实例: 可变对象在函数里修改了参数,那么在调用这个函数的函数里,原始的参数也被改变了,例如:
def changeme(mylist):
# 修改传入的列表
mylist.append([1, 2, 3, 4])
print("函数内取值: ", mylist)
return
# 调用changeme函数
mylist = [10, 20, 30]
changeme(mylist)
print("函数外取值: ", mylist)
2
3
4
5
6
7
8
9
10
传入函数的和在末尾添加新内容的对象用的是同一个引用。

# 参数
以下是调用函数时可使用的正式参数类型:
- 必需参数
- 关键字参数
- 默认参数
- 不定长参数
必需参数: 必需参数须以正确的顺序传入函数。调用时的数量必需和声明时的一样。调用printme()函数,必需传入一个参数,不然会出现语法错误:
# 可写函数说明
def printme(str):
# 打印任何传入的字符串
print(str)
return
# 调用printme函数,不加参数会报错
printme()
2
3
4
5
6
7
8
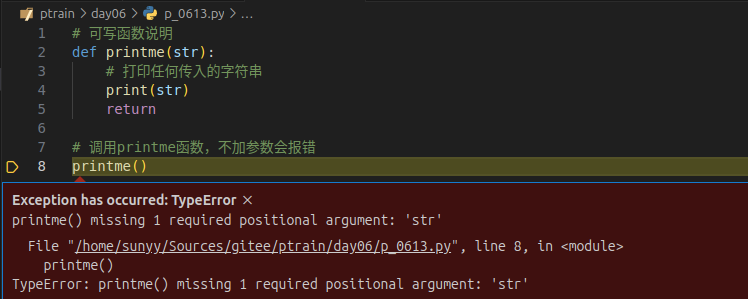
关键字参数: 关键字参数和函数调用关系紧密,函数调用使用关键字参数来确定传入的参数值。使用关键字参数允许函数调用时参数的顺序与声明时不一致,因为Python解释器能够用参数名匹配参数值。
# 可写函数说明
def printme(str):
"打印任何传入的字符串"
print(str)
return
# 调用printme函数
printme(str="菜鸟教程")
2
3
4
5
6
7
8
# 可写函数说明
def printinfo(name, age):
"打印任何传入的字符串"
print("名字: ", name)
print("年龄: ", age)
return
# 调用printinfo函数
printinfo(age=50, name="runoob")
2
3
4
5
6
7
8
9
默认参数: 调用函数时,如果没有传递参数,则会使用默认参数。以下实例中如果没有传入age参数,则使用默认值:
# 可写函数说明
def printinfo(name, age = 35):
"打印任何传入的字符串"
print("名字: ", name)
print("年龄: ", age)
return
# 调用printinfo函数
printinfo(age=50, name="runoob")
print("-----------------------")
printinfo(name="runoob")
2
3
4
5
6
7
8
9
10
11
不定长参数: 有时可能需要一个函数处理比当初声明时更多的参数,这些参数叫做不定长参数,和上述2中参数不同,声明时不会命名。基本语法如下:
def functionname([formal_args,] *var_args_tuple):
"函数_文档字符串"
function_suite
return [expression]
2
3
4
加了星号*的参数会以元组(tuple)的形式导入,存放所有未命名的变量参数。
# 可写函数说明
def printinfo(arg1, *vartuple):
"打印任何传入的参数"
print("输出: ")
print(arg1)
print(vartuple)
# 调用printinfo函数
printinfo(70, 60, 50)
2
3
4
5
6
7
8
9

如果在函数调用时没有指定参数,它就是一个空元组。也可以不向函数传递未命名的变量,如下:
# 可写函数说明
def printinfo(arg1, *vartuple):
"打印任何传入的参数"
print("输出: ")
print(arg1)
for var in vartuple:
print(var)
return
# 调用printinfo函数
printinfo(10)
printinfo(70, 60, 50)
2
3
4
5
6
7
8
9
10
11
12

还有一种就是参数带两个星号**基本语法如下:
def functionname([formal_args,] **var_args_dict):
"函数_文档字符串"
function_suite
return [expression]
2
3
4
加了两个星号**的参数会以字典的形式导入。
# 可写函数说明
def printinfo(arg1, **vardict):
"打印任何传入的参数"
print("输出: ")
print(arg1)
print(vardict)
# 调用printinfo函数
printinfo(1, a=2, b=3)
2
3
4
5
6
7
8
9

声明函数时,参数中星号*可以单独出现,例如:
def f(a, b, *, c):
return a + b + c
2
如果单独出现星号*,则星号*后的参数必须用关键字传入:
def f(a, b, *, c):
return a + b + c
# f(1, 2, 3) # 报错
f(1, 2, c=3)
2
3
4
5
6
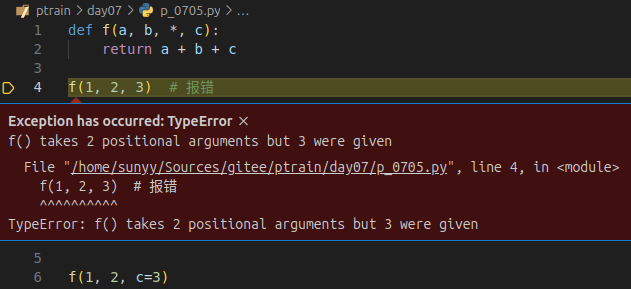
# 匿名函数
Python使用lambda来创建匿名函数。所谓匿名,即不再使用def语句这样标准的形式定义一个函数。
lambda只是一个表达式,函数体比def简单很多。- lambda的主体是一个表达式,而不是一个代码块。仅仅能在lambda表达式中封装有限的逻辑进去。
- lambda函数拥有自己的命名空间,且不能访问自己参数列表之外或全局命名空间里的参数。
- 虽然lambda函数看起来只能写一行,却不等同于C或C++的内联函数,内联函数的目的是调用小函数时不占用栈内存从而减少函数调用的开销,提高代码的执行速度。
语法: lambda [arg1 [, arg2, ... ...argn]]:expression
x = lambda a : a + 10
print(x(5))
2
# 可写函数说明
sum = lambda arg1, arg2: arg1 + arg2
# 调用sum函数
print("相加后的值为: ", sum(10, 20))
print("相加后的值为: ", sum(20, 20))
2
3
4
5
6

可以将匿名函数封装在一个函数内,这样可以使用同样的代码来创建多个匿名函数。以下实例将匿名函数封装在myfunc函数中,通过传入不同的参数来创建不同的内名函数:
def myfunc(n):
return lambda a : a * n
mydoubler = myfunc(2)
mytripler = myfunc(3)
print(mydoubler(11))
print(mytripler(11))
2
3
4
5
6
7
8

# return 语句
return [表达式]语句用于退出函数,选择性地向调用方返回一个表达式。不带参数值的return语句返回None:
# 可写函数说明
def sum(arg1, arg2):
# 返回2个参数的和
total = arg1 + arg2
print("函数内: ", total)
return total
# 调用sum函数
total = sum(10, 20)
print("函数外: ", total)
2
3
4
5
6
7
8
9
10

# 强制位置参数
Python3.8新增了一个函数形参语法/用来指明函数形参必须使用指定位置参数,不能使用关键字参数的形式。在以下例子中,形参a和b必须使用指定位置参数,c或d可以是位置形参或关键字形参,而e和f要求为关键字形参:
def f(a, b, /, c, d, *, e, f):
print(a, b, c, d, e, f)
# f(10, 20, 30, d=40, e=50, f=60) # 正确的使用方法
# f(10, b=20, c=30, d=40, e=50, f=60) # b 不能使用关键字参数的形式
# f(10, 20, 30, 40, 50, f=60) # e 必须使用关键字参数的形式
2
3
4
5
6
# Python3 lambda
Python使用lambda来创建匿名函数。lambda函数是一种小型、匿名的、内联函数,它可以具有任意数量的参数,但只能有一个表达式。匿名函数不需要使用def关键字定义完整函数。lambda函数通常用于编写简单的、单行的函数,通常在需要函数作为参数传递的情况下使用,例如在map(), filter(), reduce()等函数中。
lambda函数特点:
- lambda函数是匿名的,它们没有函数名称,只能通过赋值给变量或作为参数传递给其他函数来使用
- lambda函数通常只包含一行代码,这使得它们适用于编写简单的函数。
lambda语法格式: lambda arguments: expression
- lambda是Python的关键字,用于定义lambda函数。
- arguments是参数列表,可以包含零个或多个参数,但必须在冒号(
:)前指定 - expression是一个表达式,用于计算并返回函数的结果
f = lambda: "Hello, world!"
print(f()) # 输出: Hello, world!
2
lambda函数也可以设置多个参数,参数使用逗号,隔开:
x = lambda a, b : a * b
print(x(5, 6))
x = lambda a, b, c : a + b + c
print(x(5, 6, 2))
2
3
4
5
lambda函数通常与内置函数如map(), filter(), reduce()一起使用,以便在集合上执行操作:
numbers = [1, 2, 3, 4, 5]
squared = list(map(lambda x : x**2, numbers))
print(squared)
2
3

numbers = [1, 2, 3, 4, 5, 6, 7, 8]
even_numbers = list(filter(lambda x : x % 2 == 0, numbers))
print(even_numbers) # 输出: [2, 4, 6, 8]
2
3
from functools import reduce
numbers = [1, 2, 3, 4, 5]
# 使用 reduce() 和 lambda 函数计算乘积
product = reduce(lambda x, y : x * y, numbers)
print(product) # 输出: 120
2
3
4
5
6
7
8
上面的实例中,reduce()函数通过遍历numbers列表,并使用lambda函数将累积的结果不断更新,最终得到了1 * 2 * 3 * 4 * 5 = 120
# Python3 装饰器
装饰器(decorators)是Python中的一种高级功能,它允许动态地修改函数或类的行为。装饰器是一种函数,它接受一个函数作为参数,并返回一个新的函数或修改原来的函数。装饰器的语法使用@decorator_name来应用在函数或方法上。Python还提供了一些内置的装饰器,比如@staticmethod和@classmethod,用于定义静态方法和类方法。
装饰器的应用场景:
- 日志记录: 装饰器可用于记录函数的调用信息、参数和返回值。
- 性能分析: 可以使用装饰器来测量函数的执行时间
- 权限控制: 装饰器可用于限制对某些函数的访问权限。
- 缓存: 装饰器可用于实现函数结果的缓存,以提高性能。
基本语法: Python装饰允许在不修改原有函数代码的基础上,动态地增加或修改函数的功能,装饰器本质上是一个接收函数作为输入并返回一个新的包装过后的函数的对象。
def decorator_function(original_function):
def wrapper(*args, **kwargs):
# 这里是在调用原始函数前添加的新功能
before_call_code()
result = original_function(*args, **kwargs)
# 这里是在调用原始函数后添加的新功能
after_call_code()
return result
return wrapper
# 使用装饰器
@decorator_function
def target_function(arg1, arg2):
pass # 原始函数的实现
2
3
4
5
6
7
8
9
10
11
12
13
14
:::info 解析
decorator是一个装饰器函数,它接收一个函数func作为参数,并返回一个内部函数wrapper,在wrapper函数内部,可以执行一些额外的操作,然后调用原始函数func,并返回其结果。
decorator_function是装饰器,它接收一个函数original_function作为参数wrapper是内部函数,它是实际会被调用的新函数,它包裹了原始函数的调用,并在其前后增加了额外的行为。- 当使用
@decorator_function前缀在target_function定义前,Python会自动将target_function作为参数传递给decorator_function,然后将返回的wrapper函数替换掉原来的target_function。 :::
使用装饰器: 装饰器通过@符号应用在函数定义之前,例如:
@time_logger
def target_function():
pass
2
3
等同于:
def target_function():
pass
target_function = time_logger(target_function)
2
3
这会将target_function函数传递给decorator装饰器,并将返回的函数重新赋值给target_function。 从而,每次调用target_function时,实际上是调用了经过装饰器处理后的函数。通过装饰器,开发者可以在保持代码整洁的同时,灵活且高效地扩展程序的功能。
带参数的装饰器: 装饰器函数也可以接受参数
def repeat(n):
def decorator(func):
def wrapper(*args, **kwargs):
for _ in range(n):
result = func(*args, **kwargs)
return result
return wrapper
return decorator
@repeat(3)
def greet(name):
print(f"Hello, {name}!")
greet("Alice")
2
3
4
5
6
7
8
9
10
11
12
13
14

以上代码中repeat函数是一个带参数的装饰器,它接受一个整数参数n,然后返回一个装饰器函数。该装饰器函数内部定义了wrapper函数,在调用原始函数之前重复执行n次,因此,greet函数在被@repeat(3)装饰后,会打印三次问候。
类装饰器: 除了函数装饰器,Python还支持类装饰器。类装饰器是包含__call__方法的类,它接受一个函数作为参数,并返回一个新的函数。
class DecoratorClass:
def __init__(self, func):
self.func = func
def __call__(self, *args, **kwds):
# 在调用原始函数之前/之后执行的代码
result = self.func(*args, **kwds)
# 在调用原始函数之后执行的代码
return result
@DecoratorClass
def my_function():
pass
2
3
4
5
6
7
8
9
10
11
12
13
# Python3 数据结构
# 列表
Python列表是可变的,这是它区别于字符串和元组的最重要的特点,一句话概括即: 列表可以修改,而字符串和元组不能。
| 方法 | 描述 |
|---|---|
list.append(x) | 把一个元素添加到列表的结尾,相当于a[len(a):] = [x] |
list.extend(L) | 通过添加指定列表的所有元素来扩充列表,相当于a[len(a):] = L |
list.insert(i, x) | 在指定位置插入一个元素,第一个参数是准备插入到其前面的那个元素的索引,例如a.insert(0, x)会插入到整个列表之前,而a.inert(len(a), x)相当于a.append(x) |
list.remove(x) | 删除列表中值为x的第一个元素,如果没有这样的元素,就会返回一个错误。 |
list.pop([i]) | 从列表的指定位置移除元素,并将其返回。如果没有指定索引,a.pop()返回最后一个元素,元素随即从列表中被移除。(方法中i两边的方括号表示这个参数是可选的,而不是要求输入一对方括号) |
list.clear() | 移除列表中的所有项,等于del a[:] |
list.index(x) | 返回列表中第一个值为x的元素的索引,如果没有匹配的元素就会返回一个错误 |
list.count(x) | 返回x在列表中出现的次数 |
list.sort() | 对列表中的元素进行排序 |
list.reverse() | 倒排列表中的的元素 |
list.copy() | 返回列表的浅复制,等于a[:] |
>>> a = [66.25, 333, 333, 1, 1234.5]
>>> print(a.count(333), a.count(66.25), a.count('x'))
2 1 0
>>> a.insert(2, -1)
>>> a.append(333)
>>> a
[66.25, 333, -1, 333, 1, 1234.5, 333]
>>> a.index(333)
1
>>> a.remove(333)
>>> a
[66.25, -1, 333, 1, 1234.5, 333]
>>> a.reverse()
>>> a
[333, 1234.5, 1, 333, -1, 66.25]
>>> a.sort()
>>> a
[-1, 1, 66.25, 333, 333, 1234.5]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
类似insert, remove, sort等修改列表的方法没有返回值。
# 将列表当做栈使用
在Python中,可以使用列表(list)来实现栈的功能,栈是一种后进先出(LIFO, Last-In-First-Out)数据结构,意味着最后添加的元素最先被移除。列表提供了一些方法,使其非常适合用于栈操作,特别是append()和pop()方法。用append()方法可以把一个元素添加到栈顶,用不指定索引的pop()方法可以把一个元素从栈顶释放出来。
栈操作:
- 压入(Push): 将一个元素添加到栈的顶端
- 弹出(Pop): 移除并返回栈顶元素
- 查看栈顶元素(Peek/Top): 返回栈顶元素而不移除它
- 检查是否为空(IsEmpty): 检查栈是否为空
- 获取栈的大小(Size): 获取栈中元素的数量
- 创建一个空栈
stack = []
- 压入(Push)操作,使用
append()方法将元素添加到栈的顶端
stack.append(1)
stack.append(2)
stack.append(3)
print(stack) # 输出: [1, 2, 3]
2
3
4
- 弹出(Pop)操作,使用
pop()方法移除并返回栈顶元素:
top_element = stack.pop()
print(top_element) # 输出: 3
print(stack) # 输出: [1, 2]
2
3
- 查看栈顶元素(Peek/Top),直接访问列表中的最后一个元素,但不移除:
top_element = stack[-1]
print(top_element) # 输出: 2
2
- 检查是否为空(IsEmpty)
is_empty = len(stack) == 0
print(is_empty) # 输出: False
2
- 获取栈的大小(Size),使用
len()函数获取栈中元素的数量
size = len(stack)
print(size) # 输出: 2
2
class Stack:
def __init__(self):
self.stack = []
def push(self, item):
self.stack.append(item)
def pop(self) :
if not self.is_empty():
return self.stack.pop()
else:
raise IndexError("pop from empty stack")
def peek(self):
if not self.is_empty():
return self.stack[-1]
else:
raise IndexError("peek from empty stack")
def is_empty(self):
return len(self.stack) == 0
def size(self):
return len(self.stack)
# 使用实例
stack = Stack()
stack.push(1)
stack.push(2)
stack.push(3)
print("栈顶元素: ", stack.peek()) # 输出: 栈顶元素: 3
print("栈大小: ", stack.size()) # 输出: 栈大小: 3
print("弹出元素: ", stack.pop()) # 输出: 弹出元素: 3
print("栈是否为空: ", stack.is_empty()) # 输出: 栈是否为空: False
print("栈大小: ", stack.size()) # 输出: 栈大小: 2
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
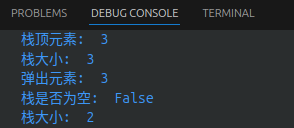
# 将列表当做队列使用
在Python中,列表(list)可以用作队列(queue),但由于列表的特点,直接使用列表实现队列并不是最优选择。队列是一种先进先出(FIFO, First-In-First-Out)的数据结构,意味着最早添加的元素最先被移除。使用列表时,如果频繁地在列表的开头插入或删除元素,性能会受到影响,因为这些操作的时间复杂度是O(n),为了解决这个问题,Python提供了collections.deque,它是双端队列,可以在两端高效地添加和删除元素。
使用collections.deque实现队列:
from collections import deque
# 创建一个空队列
queue = deque()
# 向队尾添加元素
queue.append('a')
queue.append('b')
queue.append('c')
print("队列状态: ", queue) # 输出: 队列状态: deque(['a', 'b', 'c'])
# 从队首移除元素
first_element = queue.popleft()
print("移除的元素: ", first_element) # 输出: 移除的元素: a
print("队列状态: ", queue) # 输出: 队列状态: deque(['b', 'c'])
# 查看队首元素(不移除)
front_element = queue[0]
print("队首元素: ", front_element) # 输出: 队首元素: b
# 检查队列是否为空
is_empty = len(queue) == 0
print("队列是否为空: ", is_empty) # 输出: 队列是否为空: False
# 获取队列大小
size = len(queue)
print("队列大小: ", size) # 输出: 队列大小: 2
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
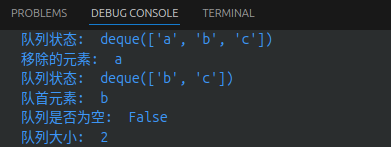
# 列表推导式
列表推导式提供了从序列创建列表的简单途径。通常应用程序将一些操作应用于某个序列的每个元素,用其获得的结果作为生成新列表的元素,或者根据确定的判定条件创建子序列。每个列表推导式都在for之后跟一个表达式,然后有零到多个for或if子句。返回结果是一个根据表达从其后的for和if上下文环境中生成出来的列表。如果希望表达式推导出一个元组,就必须使用括号。
vec = [2, 4, 6]
vec2 = [3*x for x in vec]
print(vec2)
vec3 = [[x, x**2] for x in vec]
print(vec3)
freshfruit = [' banana', ' loganberry ', 'passion fruit ']
freshfruit2 = [weapon.strip() for weapon in freshfruit]
print(freshfruit2)
vec4 = [3*x for x in vec if x > 3]
print(vec4)
vec5 = [3*x for x in vec if x < 2]
print(vec5)
list1 = [2, 4, 6]
list2 = [4, 3, -9]
list3 = [x*y for x in list1 for y in list2]
print(list3)
list4 = [x+y for x in list1 for y in list2]
print(list4)
list5 = [list1[i]*list2[i] for i in range(len(list1))]
print(list5)
list6 = [str(round(355/113, i)) for i in range(1, 6)]
print(list6)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
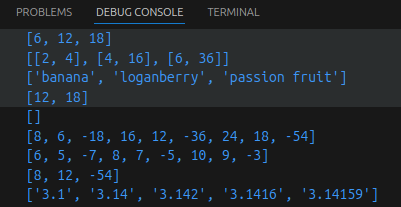
# 嵌套列表解析
Python的列表可以嵌套,如下3X4的矩阵列表:
# 3X4的矩阵
matrix = [
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]
]
# 将3X4的矩阵列表转换为4X3列表
matrix2 = [[row[i] for row in matrix] for i in range(4)]
print(matrix2)
# [[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]
2
3
4
5
6
7
8
9
10
11
# 以上实例也可以使用以下方法实现
transposed = []
for i in range(4):
transposed.append([row[i] for row in matrix])
print(transposed)
# 另外一种实现方法
transposed2 = []
for i in range(4):
# the following 3 lines implement the nested listcomp
transposed_row = []
for row in matrix:
transposed_row.append(row[i])
transposed2.append(transposed_row)
print(transposed2)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# del 语句
使用del语句可以从一个列表中根据索引来删除一个元素,而不是值来删除元素,这与使用pop()返回一个值不同,可以用del语句从列表中删除一个切割,或清空整个列表。如:
a = [-1, 1, 66.25, 333, 333, 1234.5]
del a[0]
print(a)
del a[2:4]
print(a)
del a[:]
print(a)
# 也可以用del删除实体变量
del a
2
3
4
5
6
7
8
9
10
11
12
# 元组和序列
元组由若干逗号分隔的值组成,如:
t = 12345, 54321, 'hello!'
print(t[0])
print(t)
# Tuples may be nested
u = t, (1, 2, 3, 4, 5)
print(u)
2
3
4
5
6

元组在输出时总是有括号的,以便于正确表达嵌套结构,在输入时可能有或没有括号,不过括号通常是必须的(如果元组是更大的表达式的一部分)
# 集合
集合是一个无序不重复元素的集,基本功能包括关系测试和消除重复元素。可以用大括号{}创建集合,注意: 如果要创建一个空集合,必须用set()而不是{}; 后者创建一个空的字典。
basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
print(basket) # 删除重复的
has_orange = 'orange' in basket # 监测成员
print(has_orange)
has_crabgrass = 'crabgrass' in basket
print(has_crabgrass)
# 以下演示了两个集合的操作
a = set('abracadabra')
b = set('alacazam')
print(a) # a 中唯一的字母
print(a - b) # 在 a 中的字母,但不在 b 中
print(a | b) # 在 a 或 b 中的字母
print(a & b) # 在 a 和 b 中都有的字母
print(a ^ b) # 在 a 或 b 中的字母,但不同时在 a 和 b 中
# 集合也支持推导式
c = {x for x in 'abracadabra' if x not in 'abc'}
print(c)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
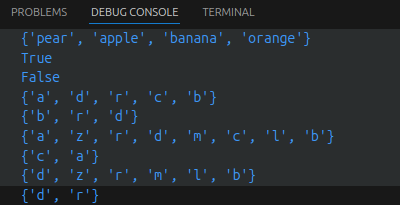
# 字典
序列是以连续的整数为索引,与此不同的是,字典以关键字为索引,关键字可以是任意不可变类型,通常用字符串或数值。理解字典的最佳方式是把它看作无序的键=>值对集合。在同一个字典之内,关键字必须是互不相同。一对大括号创建一个空的字典: {}
tel = {'jack': 4098, 'sape': 4139}
tel['guido'] = 4127
print(tel)
print(tel['jack'])
del tel['sape']
tel['irv'] = 4127
print(tel)
keys = list(tel.keys())
print(keys)
sorted_keys = sorted(tel.keys())
print(sorted_keys)
has_guido = 'guido' in tel
print(has_guido)
has_jack = 'jack' in tel
print(has_jack)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
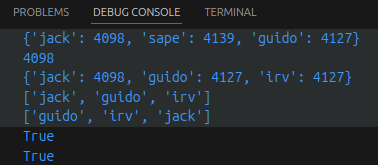
构造函数dict()直接从键值对元组列表中构建字典。如果有固定的模式,列表推导式指定特定的键值对:
a = dict([('sape', 4139), ('guido', 4127), ('jack', 4098)])
print(a)
# 字典推导可以用来创建任意键和值的表达式词典
b = {x: x**2 for x in (2, 4, 6)}
print(b)
# 如果关键字只是简单的字符串,使用关键字参数指定键值对有时候更方便
c = dict(sape=4139, guido=4127, jack=4098)
print(c)
2
3
4
5
6
7
8
9
10
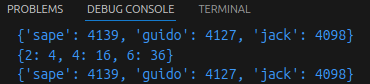
# 遍历技巧
在字典中遍历时,关键字和对应的值可以使用items()方法同时解读出来
# items()
knights = {'gallahad': 'the pure', 'robin': 'the brave'}
for k, v in knights.items():
print(k, v)
# 在序列中遍历时,索引位置和对应值可以使用enumerate()函数同时得到
for i, v in enumerate(['tic', 'tac', 'toe']):
print(i, v)
# 同时遍历两个或更多的序列,可以使用zip()组合
questions = ['name', 'quest', 'favorite color']
answers = ['lancelot', 'the holy grail', 'blue']
for q, a in zip(questions, answers):
print('What is your {0}? It is {1}.'.format(q, a))
# 要反向遍历一个序列,首先指定这个序列,然后调用reversed()函数
for i in reversed(range(1, 10, 2)):
print(i)
# 要按顺序遍历一个序列,使用sorted()函数返回一个已排序的序列,并不修改原值
basket = ['apple', 'orange', 'apple', 'pear', 'orange', 'banana']
for f in sorted(set(basket)):
print(f)
print(basket)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
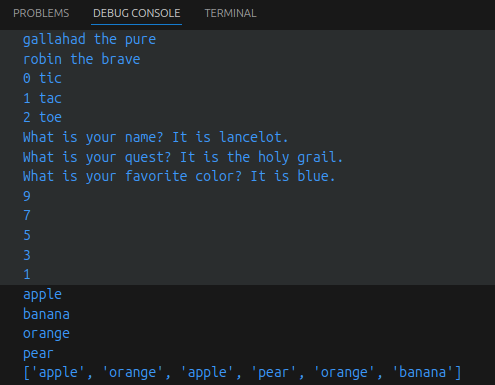
# Python3 模块
在前面,有用Python解释器编程,如果从Python解释器退出再进入,那么定义的所有方法和变量就都消失了。为此Python提供了一个方案,把定义存放在文件中,为一些脚本或者交互式的解释器实例使用,这个文件称为模块。 模块是一个包含所有定义的函数和变量的文件,其后缀名是.py。模块可以被别的程序引入,以使用该模块中的函数等功能。这也是使用Python标准库的方法。
import sys
print('命令行参数如下:')
for i in sys.argv:
print(i)
print('\n\nPython 路径为: ', sys.path, '\n')
2
3
4
5
6
7

import sys引入python标准库中的sys.py模块,这是引入某一模块的方法sys.argv是一个包含命令行参数的列表sys.path包含了一个Python解释器自动查找所需模块的路径的列表。
# import 语句
使用Python源文件,只需在另一个源文件里执行import语句,如下:
import module1[, module2[, ... moduleN]]
当解释器遇到import语句,如果模块在当前的搜索路径就会被导入。搜索路径是一个解释器会先进行搜索的所有目录的列表。如果要导入模块support,需要把命令放在脚本的顶端。
# test.py 引入 support 模块
# 导入模块
import support
# 可以调用模块里包含的函数
support.print_func("Runoob")
# 输出 Hello : Runoob
2
3
4
5
6
7
8
一个模块只会被导入一次,不管执行了几次import。这样可以防止导入模块被一遍又一遍地执行。那么,当使用import语句的时候,Python解释器是怎么找到对应的文件呢?
这涉及到Python的搜索路径,搜索路径是由一系列目录名组成的,Python解释器就依次从这些目录中去寻找所引入的模块。有点像环境变量,事实上,也可以通过定义环境变量的方式来搜索路径。搜索路径是在Python编译或安装的时候确定的,安装新的库应该也会修改。搜索路径被存储在sys模块中的path变量。
import sys
print(sys.path)
2

sys.path输出是一个列表,其中第一项是当前目录,如果在当前目录下与要引入模块同名的文件,就会把要引入的模块屏蔽掉。了解了搜索路径的概念,就可以在脚本中修改sys.path来引入一些不在搜索路径中的模块。
现在,在解释器的当前目录或者sys.path中的一个目录里面来创建一个fibo.py的文件,如下:
# 斐波那契数列模块
def fib(n): # 定义到 n 的斐波那契数列
a, b = 0, 1
while b < n:
print(b, end=' ')
a, b = b, a + b
print()
def fib2(n): # 返回到 n 的斐波那契数列
result = []
a, b = 0, 1
while b < n:
result.append(b)
a, b = b, a + b
return result
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# import_fibo.py 文件
import fibo # 这样并没有把直接定义在fibo中的函数名称写入到当前符号表里,只是把模块fibo的名字写到了那里,可以使用模块名来访问函数
fibo.fib(1000)
result = fibo.fib2(100)
print(result)
print(fibo.__name__)
# 如果经常使用一个函数,可以把它赋值给一个本地名称
# fib = fibo.fib
# fib(500)
2
3
4
5
6
7
8
9
10
11
12
13
# from ... import 语句
Python的from语句可以从模块中导入一个指定的部分到当前命名空间中,语法:
from modname import name1[, name2[, ... nameN]]
比如,要导入模块fibo的fib函数,可以:
from fibo import fib, fib2
fib(500)
# 这个声明不会把整个fibo模块导入到当前的命名空间中,它只会将fibo里的fib函数引入进来
2
3
4
# from ... import * 语句
把一个模块的所有内容全都导入到当前的命名空间也是可行的,只需:
from modname import *
# 这提供了一个简单的方法来导入一个模块中的所有项目,然而这种声明不该被过多地使用。
2
3
# 深入模块
模块除了方法定义,还可以包括可执行的代码,这些代码一般用来初始化这个模块。这些代码只有在第一次被导入时才会被执行。每个模块有各自独立的符号表,在模块内部为所有的函数当做全局符号表来使用。所以,模块的作者可以大胆的在模块内部使用这些全局变量,而不用担心把其他用户的全局变量搞混。从另一个方面,也可以通过modname.itemname这样的表示来访问模块内的函数。模块是可以导入其他模块的,在一个模块(或者脚本,或者其他地方)的最前面使用import来导入另一个模块,被导入的模块名称将被放入当前操作的模块的符号表中。还有一种导入方法,可以使用import直接把模块内(函数,变量)名称导入到当前操作模块,比如:
from fibo import fib, fib2
fib(500)
2
这种导入的方法不会把被导入的模块的名称放在当前的字符表中(所以上面的例子,fibo这个名称是没有意义的),还有一种方法,可以一次性把模块中的所有(函数,变量)名称都导入到当前模块的字符表:
from fibo import *
fib(500)
2
这将把所有的名字都导入进来,但是那些单一下划线(_)开头的名字不在此列,大多数情况,不使用这种方法,因为引入的其他来源的命名,很可能覆盖已有的定义。
# __name__ 属性
一个模块被另一个程序第一次引入时,其主程序将运行。如果想在模块被引入时,模块中的某一程序块不执行,可以用__name__属性来使该程序块仅在该模块自身运行时执行。
# using_name.py
if __name__ == '__main__':
print('程序自身在运行')
else:
print('来自另一个模块')
2
3
4
5

# import_using_name.py
import using_name
2

:::info 说明
每个模块都有一个__name__属性,当其值是__main__时,表明该模块自身在运行,否则是被引入。__name__和__main__底下是双下划线,_ _去掉中间的空格。
:::
# dir() 函数
内置的函数dir()可以找到模块内定义的所有名称,以一个字符串列表的形式返回:
import fibo, sys
print(dir(fibo))
print(dir(sys))
2
3

如果没有给定参数,那么dir()函数会罗列出当前定义的所有名称:
a = [1, 2, 3, 4, 5]
import fibo
fib = fibo.fib
print(dir()) # 得到一个当前模块中定义的属性列表
a = 5 # 建立一个新的变量
print(dir())
del a # 删除变量名 a
print(dir())
2
3
4
5
6
7
8
9

# 标准模块
Python本身带着一些标准的模块库,有些模块直接被构建在解释器里,这些虽然不是一些语言内置的功能,但却能很高效的使用,甚至是系统级调用也没问题。这些组件会根据不同的操作系统进行不同的形式的配置,比如winreg就只会提供给Windows系统。有一个特别的模块sys,它内置在每一个Python解释器中,变量sys.ps1和sys.ps2定义了主提示符和副提示符所对应的字符串:

# 包
包是一种管理Python模块命名空间的形式,采用点模块名称。比如一个模块的名称是A.B,那么他表示一个包A中的子模块B。就好像使用模块的时候,不用担心不同模块之间的全局变量相互影响,采用点模块名称这种形式也不用担心不同库之间的模块重名的情况。这样不同的作者都可以提供NumPy模块,或者是Python图形库。
布防假设想设计一套统一处理声音文件和数据的模块(或者称之为一个包)。现存很多种不同的音频文件格式(基本上都是通过后缀名区分的,例如: .wav, :file:.aiff, :file:.au),所以需要一组不断增加的模块,用来在不同的格式之间转换。并且针对这些音频数据,还有很多不同的操作(比如混音,添加回声,增加均衡器功能,创建人造立体声效果),所以需要一组怎么也写不完的模块来处理这些操作。
这里给出了一种可能的结构(在分层的文件系统中):

在导入一个包的时候,Python会根据sys.path中的目录来寻找这个包中包含的子目录。目录只有包含一个叫做__init__.py的文件才会被认作是一个包,主要是为了避免一些滥俗的名字(比如string)不小心的影响搜索路径中的有效模块。最简单的情况,放一个空的:file:__init__.py就可以了,当然这个文件中也可以包含一些初始化代码或者为__all__变量赋值。
用户可以每次只导入一个包里面的特定模块:
import sound.effects.echo
这将会导入子模块: sound.effects.echo,他必须使用全名去访问:
sound.effects.echo.echofilter(input, output, delay=0.7, atten=4)
还有一种导入子模块的方法是:
from sound.effects import echo
这同样会导入子模块: echo,并且不需要那些冗长的前缀,因此可以这样使用:
echo.echofilter(input, output, delay=0.7, atten=4)
还有一种变化就是直接导入一个函数或者变量:
from sound.effects.echo import echofilter
同样的,这种方法会导入子模块: echo,并且可以直接使用他的echofilter()函数:
echofilter(input, output, delay=0.7, atten=4)
注意
当使用from package import item这种形式的时候,对应的item既可以是包里面的子模块(子包),或者包里面定义的其他名称,比如函数,类或这变量。
import语法会首先把item当做一个包定义的名称,如果没找到,再试图按照一个模块去导入。如果还没找到,抛出一个:exc:ImportError。
反之,如果使用形如import item.subitem.subsubitem这种导入形式,除了最后一项,都必须是包,而最后一项则可以是模块或者是包,但是不可以是类,函数或者变量的名字。
# 从一个包中导入*
如果使用from sound.effects import *会发生什么?
Python会进入文件系统,找到包里面所有的子模块,然后一个一个的把它们都导入进来。但这个方法在Windows平台上会出现问题,因为Windows是一个不区分大小写的系统。在Windows平台上,无法确定一个叫做ECHO.py的文件导入为模块是echo还是Echo,或者是ECHO。为了解决这个问题,需要提供一个精确包的索引。
导入语句遵循如下规则: 如果包定义文件__init__.py存在一个叫做__all__的列表变量,那么在使用from package import *的时候就把这个列表中的所有名字作为包内容导入。作为包的作者,在更新包之后需要保证__all__也更新。
# file:sounds/effects/__init__.py
__all__ = ["echo", "surround", "reverse"]
2
这表示当使用from sound.effects import *这种用法时,只会导入包里面这三个子模块。如果__all__没有定义,那么使用from sound.effects import *这种语法时,就不会导入包sound.effects里的任何子模块。他只是把包sound.effects和它里面定义的所有内容导入进来(可能运行__init__.py里定义的初始化代码)。这会把__init__.py里面定义的所有名字导入进来,并且不会破坏这句之前导入的所有明确指定的模块。
import sound.effects.echo
import sound.effects.surround
from sound.effects import *
2
3
这个例子,在执行from .. import前,包sound.effects中的echo和surround模块都被导入到当前的命名空间中(当然如果定义了__all__就更没问题了)
通常并不建议使用*这种方法来导入模块,因为这种方法经常会导致代码可读性降低。需要注意的是: from package import specific_submodule这种方法永远不会有错。事实上,这也是推荐的方法,除非要导入的子模块有可能和其他包的子模块重名。如果在结构中包是一个子包(比如这个例子中对于包sound),而又想导入同级别的包,就得使用导入绝对路径来导入,比如模块sound.filters.vocoder要使用包sound.effects中的模块echo,需要写成from sound.effects import echo
from . import echo
from .. import formats
from ..filters import equalizer
2
3
无论是隐式的还是显示的相对导入都是从当前模块开始的,主模块的名字永远是__main__,一个Python应用程序的主模块,应当总是使用绝对路径引用。
包还提供了一个额外的属性__path__。这是一个目录列表,里面每一个包含的目录都有为这个包服务的__init__.py,需要在其他__init__.py被执行前定义,可以修改这个变量,用来影响包含在包里面的模块和子包。这个功能不常用,一般用来扩展包里面的模块。
# Python3 输入和输出
# 输出格式美化
Python两种输出值的方式: 表达式语句和print()函数。第三种方式是使用文件对象的write()方法,标准输出文件可以用sys.stdout引用。如果希望输出的形式更加多样,可以使用str.format()函数来格式化输出值。如果希望将输出的值转成字符串,可以使用repr()或str()函数来实现。
str(): 函数返回一个用户易读的表达形式。repr(): 产生一个解释器易读的表达形式。
s = 'Hello, Runoob'
print(str(s))
print(repr(s))
print(str(1/7))
x = 10 * 3.25
y = 200 * 200
s = 'x 的值为: ' + repr(x) + ', y 的值为: ' + repr(y) + '...'
print(s)
# repr() 函数可以转义字符串中的特殊字符
hello = 'hello, runoob\n'
print(hello)
hellos = repr(hello)
print(hellos)
# repr() 的参数可以是Python的任何对象
print(repr((x, y, ('Google', 'Runoob'))))
# 两种方式输出一个平方与立方的表
for x in range(1, 11):
print(repr(x).rjust(2), repr(x*x).rjust(3), end=' ')
# 注意前一行 end 的使用
print(repr(x*x*x).rjust(4))
for x in range(1, 11):
print('{0:2d} {1:3d} {2:4d}'.format(x, x*x, x*x*x))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
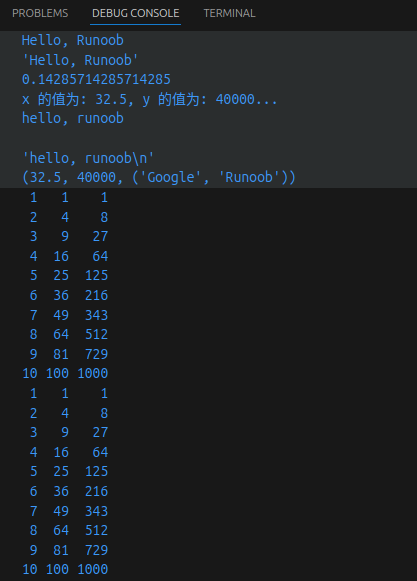
注意
在第一个例子中,每列间的空格由print()添加。这个例子展示了字符串对象的rjust()方法,它可以将字符串靠右,并在左边填充空格。还有类似的方法,如ljust()和center()。这写方法不会写任何东西,仅仅返回新的字符串。另一个方法zfill(),它会在数字的左边填充0,如下:
# zfill() 方法的使用
print('12'.zfill(5))
print('-3.14'.zfill(7))
print('3.14159265359'.zfill(5))
2
3
4

s = 'Hello, Runoob'
print(str(s))
print(repr(s))
print(str(1/7))
x = 10 * 3.25
y = 200 * 200
s = 'x 的值为: ' + repr(x) + ', y 的值为: ' + repr(y) + '...'
print(s)
# repr() 函数可以转义字符串中的特殊字符
hello = 'hello, runoob\n'
print(hello)
hellos = repr(hello)
print(hellos)
# repr() 的参数可以是Python的任何对象
print(repr((x, y, ('Google', 'Runoob'))))
# 两种方式输出一个平方与立方的表
for x in range(1, 11):
print(repr(x).rjust(2), repr(x*x).rjust(3), end=' ')
# 注意前一行 end 的使用
print(repr(x*x*x).rjust(4))
for x in range(1, 11):
print('{0:2d} {1:3d} {2:4d}'.format(x, x*x, x*x*x))
# zfill() 方法的使用
print('12'.zfill(5))
print('-3.14'.zfill(7))
print('3.14159265359'.zfill(5))
# str.format() 的基本使用
print('{} 网址: "{}!"'.format('菜鸟教程', 'www.runoob.com'))
# 大括号及其里面的字符(称作格式化字段)将会被 format() 中的参数替换。
# 在大括号中的数字用于指向传入对象在 format() 中的位置
print('{0} 和 {1}'.format('Google', 'Runoob'))
print('{1} 和 {0}'.format('Google', 'Runoob'))
# 如果在 format() 中使用了关键字参数,那么它们的值会指向使用该名字的参数
print('{name} 网址: {site}'.format(name='菜鸟教程', site='www.runoob.com'))
# 位置及关键字参数可以任意结合
print('站点列表 {0}, {1}, 和 {other}'.format('Google', 'Runoob', other='Taobao'))
# !a 使用 ascii(), !s 使用 str(), !r 使用 repr() 可以用于在格式化某个值之前对其进行转化
import math
print('常量 PI 的值近似为: {}'.format(math.pi))
print('常量 PI 的值近似为: {!r}'.format(math.pi))
# 可选项 : 和格式标识符可以跟着字段名,允许对值进行更好的格式化,如将 PI 保留到小数点后三位
print('常量 PI 的近似值为 {0:.3f}'.format(math.pi))
# 在 : 后传入一个整数,可以保证该域至少有这么多的宽度,用于美化表格
table = {'Google': 1, 'Runoob': 2, 'Taobao': 3}
for name, number in table.items():
print('{0:10} ==> {1:10d}'.format(name, number))
# 如果有一个很长的格式化字符串,而不想将它们分开,可以在格式化时通过变量名而非位置
# 最简单的就是传入一个字典,然后使用方括号 [] 访问键值
table = {'Google': 1, 'Runoob': 2, 'Taobao': 3}
print('Runoob: {0[Runoob]:d}; Google: {0[Google]:d}; Taobao: {0[Taobao]:d}'.format(table))
# 也可以通过在 table 变量前使用 ** 来实现相同的功能
print('Runoob: {Runoob:d}; Google: {Google:d}; Taobao: {Taobao:d}'.format(**table))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
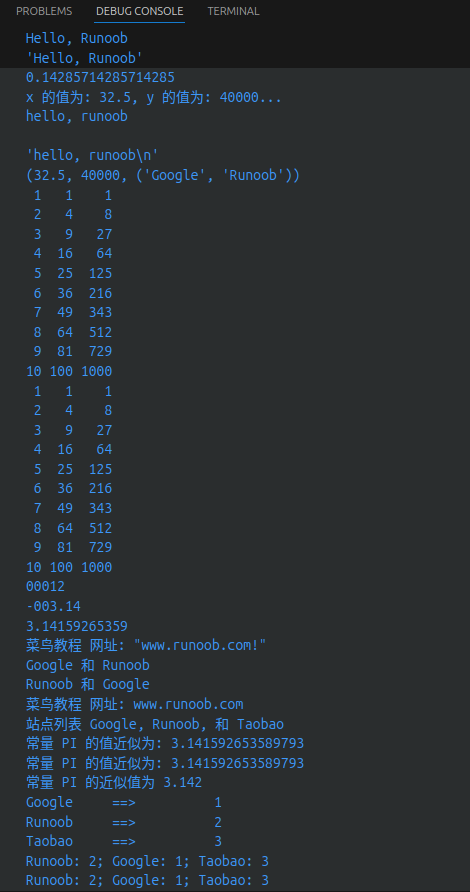
# 旧式字符串格式化
%操作符也可以实现字符串格式化,它将左边的参数作为类似 sprintf() 式的格式化字符串,而将右边的代入,然后返回格式化后的字符串:
import math
print('常量 PI 的近似值为: %5.3f' % math.pi)
2
因为 str.format() 是比较新的函数,大多数的Python代码仍然使用 % 操作符,但是因为这种旧的格式化最终会从该语言中移除,因此应该更多的使用 str.format()
# 读取键盘输入
str = input("请输入: ")
print("你输入的内容是: ", str)
2
# 读和写文件
open()将会返回一个file对象,基本语法格式: open(filename, mode)
filename: 包含了要访问的文件名称的字符串mode: 决定了打开文件的模式: 只读,写入,追加等。所有可取值见如下列表,此参数是非强制的,默认文件访问模式为只读(r)
|模式|描述||
|:--|:--|
|r|以只读方式打开文件,文件的指针会放在文件的开头,默认模式|
|rb|以二进制格式打开一个文件用于只读,文件指针将会放在文件的开头|
|r+|打开一个文件用于读写,文件指针放在文件的开头|
|rb+|以二进制格式打开一个文件用于读写,文件指针放在开头|
|w|打开一个文件只用于写入,如果该文件已经存在则打开文件,并从开头开始编辑,即原有内容会被删除,如果文件不存在,创建新文件|
|wb|以二进制文件打开一个文件只用于写入,如果该文件已经存在则打开文件,并从开头开始编辑,原有内容会被删除,如文件不存在,创建文件|
|w+|打开一个文件用于读写,如果该文件已经存在则打开文件,并从头开始编辑,原有内容会被删除,如文件不存在,创建文件|
|wb+|以二进制格式打开一个文件用于读写,如果文件存在则打开,并从头编辑,原有内容会删除,如文件不存在,创建文件|
|a|打开一个文件用于追加,如文件存在,文件指针将会放在文件结尾,新的内容会被写入到已有内容之后,如果文件不存在则创建文件|
|ab|以二进制格式打开一个文件用于追加。|
|a+|打开一个文件用于读写,如果文件存在,文件指针会放在文件的结尾|
|ab+|略|
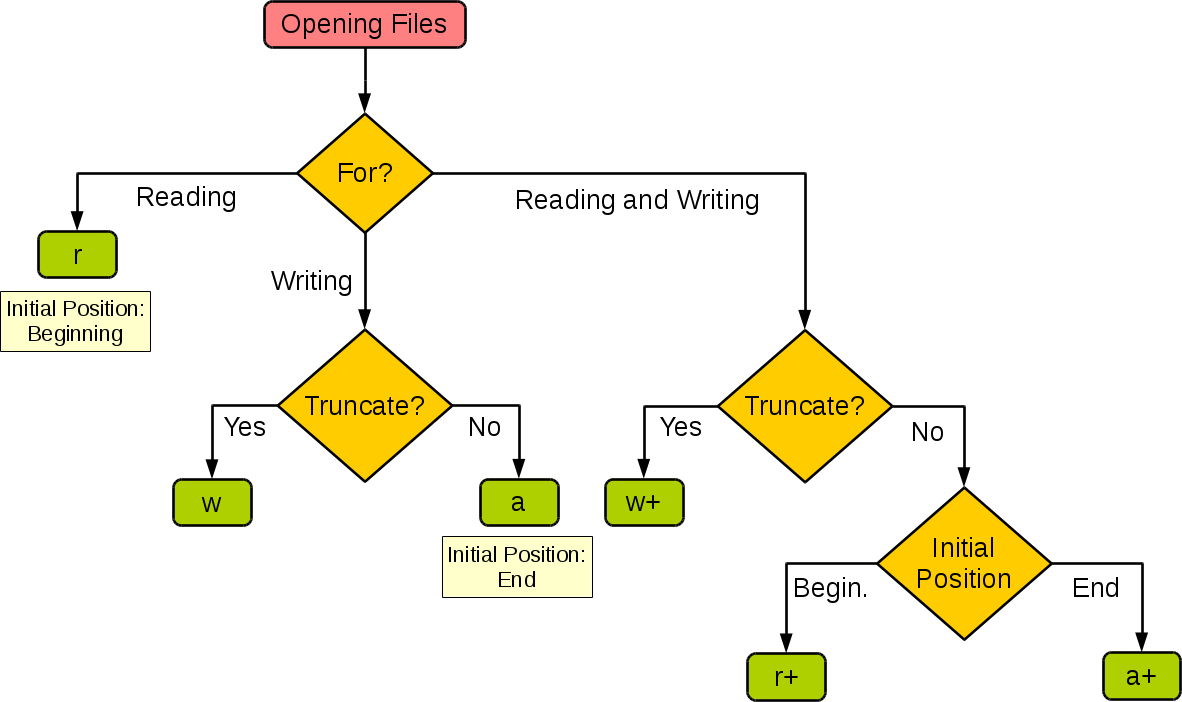
# 打开一个文件
f = open("./foo.txt", "w")
f.write("Python 是一个非常好的语言。\n是的,的确非常好!!\n")
# 关闭打开的文件
f.close()
2
3
4
5
6
- 第一个参数为要打开的文件名
- 第二个参数描述文件如何使用的字符。mode可以是r如果文件只读,w只用于写(如果存在同名文件则被删除),a用于追加文件内容;所写的任何数据都会被自动增加到末尾,r+同时用于读写,mode参数是可选的,r是默认值。
# 文件对象的方法
- f.read()
为了读取一个文件的内容,调用f.read(size)将读取一定数目的数据,然后作为字符串或字节对象返回。size是一个可选的数字类型的参数。当size被忽略了或者为负,那么该文件的所有内容都将被读取并且返回。
# 打开一个文件
f = open("./foo.txt", "r")
str = f.read()
print(str)
# 关闭文件
f.close()
2
3
4
5
6
7

- f.readline()
从文件中读取单独的一行。换行符为\n,如果返回一个空字符串,说明已经读取到最后一行。
# 打开文件
f = open("./foo.txt", "r")
str = f.readline()
print(str)
# 关闭文件
f.close()
2
3
4
5
6
7
8

- f.readlines()
返回文件中包含的所有行,如果设置可选参数sizehint,则读取指定长度的字节,并且将这些字节按行分隔。
# 打开文件
f = open("./foo.txt", "r")
str = f.readlines()
print(str)
# 关闭文件
f.close()
2
3
4
5
6
7
8

另一种方式是迭代一个文件对象然后读取每行:
# 打开文件
f = open("./foo.txt", "r")
for line in f:
print(line, end='')
# 关闭文件
f.close()
2
3
4
5
6
7
8
- f.write()
f.write(string)将string写入到文件中,然后返回写入的字符数。
# 打开文件
f = open("./foo.txt", "w")
num = f.write("Python 是一个非常号的语言。\n 是的,的确非常好!!\n Hello, World! \n")
print(num)
# 关闭文件
f.close()
2
3
4
5
6
7
8
如果需要写入一些不是字符串的东西,那么需要先进行转换:
# 打开文件
f = open("./foo.txt", "w")
value = ('www.runoob.com', 14)
s = str(value)
f.write(s)
# 关闭文件
f.close()
2
3
4
5
6
7
8
9
- f.tell()
f.tell()用于返回文件当前的读/写位置(即文件指针的位置)。文件指针表示从文件开头开始的字节数偏移量。f.tell()返回一个整数,表示文件指针的当前位置。
- f.seek()
如果要改变文件指针当前的位置,可以使用f.seek(offset, from_what)函数。f.seek(offset, whence)用于移动文件指针到指定位置。
offset表示相对于whence参数的偏移量,from_what的值,如果是0表示开头,如果是1表示当前位置,2表示文件的结尾,如:
seek(x, 0): 从起始位置即文件首行首字符开始移动x个字符seek(x, 1): 表示从当前位置往后移动x个字符seek(-x, 2): 表示从文件的结尾往前移动x个字符
f = open("./foo.txt", "rb+")
f.write(b'0123456789abcdef')
f.seek(5) # 移动到文件的第六个字节
print(f.read(1))
f.seek(-3, 2) # 移动到文件的倒数第三个字节
print(f.read(1))
2
3
4
5
6

- f.close()
关闭文件并释放系统资源,如果尝试再次调用文件,则会抛出异常。当处理一个文件对象时,使用with关键字是非常好的方式。在结束后,它会正确的关闭文件,而且比try-finally语句更简短
with open("./foo.txt", "r") as f:
read_data = f.read()
# 上面代码执行后,会正确的关闭文件,此时 f.closed()方法返回 True
2
3
4
文件对象还有其他方法,如isatty()和trucate(),但比较少用。
# pickle 模块
Python的pickle模块实现了基本的数据序列和反序列化,通过pickle模块的序列化操作能够将程序中运行的对象信息保存到文件中,永久存储。通过pickle模块的反序列化操作,能够从文件中创建上一次程序保存的对象。pickle.dump(obj, file, [,protocol])
有了pickle对象,就能对 file 以读取的形式打开: x = pickle.load(file)
说明
从file中读取一个字符串,并将它重构为原来的Python对象。file: 类文件对象,有read()和readline()接口。
import pickle
# 使用pickle模块将数据对象保存到文件
data1 = {
'a': [1, 2.0, 3, 4+6j],
'b': ('string', u'Unicode string'),
'c': None
}
selfref_list = [1, 2, 3]
selfref_list.append(selfref_list)
output = open('./data.pkl', 'wb')
# Pickle dictionary using protocol 0.
pickle.dump(data1, output)
# Pickle the list using the highest protocol available
pickle.dump(selfref_list, output, -1)
output.close()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
import pprint, pickle
# 使用pickle模块从文件中重构python对象
pkl_file = open('./data.pkl', 'rb')
data1 = pickle.load(pkl_file)
pprint.pprint(data1)
data2 = pickle.load(pkl_file)
pprint.pprint(data2)
pkl_file.close()
2
3
4
5
6
7
8
9
10
11
12

# Python3 File
# open() 方法
Python open()方法用于打开一个文件,并返回文件对象。在对文件进行处理过程都需要使用到这个函数,如果该文件无法被打开,会抛出OSError。
注意
使用open()方法一定要保证关闭文件对象,即调用close()方法。open()函数常用形式是接收两个参数: 文件名(file)和模式(mode)。
open(file, mode='r')
# 完整的语法格式为
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
2
3
4
参数说明:
file: 必需, 文件路径(相对或绝对路径)mode: 可选, 文件打开模式buffering: 设置缓冲encoding: 一般使用utf8errors: 报错级别newline: 区分换行符closefd: 传入的file参数类型opener: 设置自定义开启器, 开启器的返回值必须是一个打开的文件描述符。
mode参数有:
| 模式 | 描述 |
|---|---|
t | 文本模式(默认) |
x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
b | 二进制模式 |
+ | 打开一个文件进行更新(可读可写)。 |
U | 通用换行模式(Python3 不支持) |
r | 以只读方式打开文件。文件的指针将会放在文件的开头。默认模式 |
rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。默认模式,一般用于非文本文件如图片等。 |
r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,原有内容会被删除。如果该文件不存在,创建新文件。 |
wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如过该文件不存在,创建新文件,一般用于非文本文件如图片等。 |
w+ | 打开一个文件用于读写,如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除,如果文件不存在,创建新文件。 |
wb+ | 以二进制格式打开一个文件用于读写,如果该文件已存在则打开文件,并从头开始编辑,即原有内容会被删除。如果文件不存在,创建新文件。一般用于非文本文件如图片等。 |
a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果文件不存在,创建新文件进行写入。 |
ab | 以二进制格式打开一个文件用于追加。如果文件已存在,文件指针将会放在文件的结尾,新的内容会被写入到已有内容之后,如果文件不存在,创建文件并写入。 |
a+ | 打开一个文件用于读写,如果文件存在,文件指针放在结尾,文件打开时会是追加模式,如果文件不存在,创建文件用于读写。 |
ab+ | 以二进制格式打开文件用于追加,如果文件存在,指针放在文件结尾,如文件不存在,创建文件用于读写。 |
注意
默认为文本模式,如果需要以二进制模式打开,加b
# file 对象
file对象使用open函数来创建,下表列出了file对象常用的函数:
| 方法 | 描述 |
|---|---|
file.close() | 关闭文件,关闭后文件不能再进行读写操作 |
file.flush() | 刷新文件内部缓冲,直接把内部缓冲区的数据立刻写入文件,而不是被动的等待输出缓冲区写入 |
file.fileno() | 返回一个整型的文件描述符(file descriptor FD 整型),可以用在如os模块的read方法等一些底层操作上。 |
file.isatty() | 如果文件连接到一个终端设备返回True,否则返回False |
file.next() | Python3 中的File对象不支持next()方法 返回文件下一行。 |
file.read([size]) | 从文件读取指定的字节数,如果未给定或为负则读取所有。 |
file.readline([size]) | 读取整行,包括"\n"字符 |
file.readlines([sizeint]) | 读取所有行并返回列表,若给定sizeint>0,返回综合大约为sizeint字节的行,实际读取值可能比sizeint较大,因为需要填充缓冲区。 |
file.seek(offset[, whence]) | 移动文件读取指针到指定位置。 |
file.tell() | 返回文件当前位置。 |
file.truncate([size]) | 从文件的首行首字符开始截断,截断文件为size个字符,无size表示从当前位置截断;截断之后后面的所有字符被删除,其中windows系统下的换行代表2个字符大小。 |
file.write(str) | 将字符串写入文件,返回的是写入的字符长度。 |
file.writelines(sequence) | 向文件写入一个序列字符串列表,如果需要换行则要自己加入每行的换行符。 |
# Python3 OS
os模块提供了非常丰富的方法用来处理文件和目录,常用方法如下:
| 方法 | 描述 |
|---|---|
os.access(path, mode) | 检验权限模式 |
os.chdir(path) | 改变当前工作目录 |
os.chflags(path, flags) | 设置路径的标记为数字标记 |
os.chmod(path, mode) | 更改权限 |
os.chown(path, uid, gid) | 更改文件所有者 |
os.chroot(path) | 改变当前进程的根目录 |
os.close(fd) | 关闭文件描述符fd |
os.closerange(fd_low, fd_high) | 关闭所有文件描述符,从fd_low(包含)到fd_high(不包含),错误会忽略。 |
os.dup(fd) | 复制文件描述符fd |
os.dup2(fd, fd2) | 将一个文件描述符fd复制到另一个fd2 |
os.fchdir(fd) | 通过文件描述符改变当前工作目录 |
os.fchmod(fd, mode) | 改变一个文件的访问权限,该文件由参数fd指定,参数mode是Unix下的文件访问权限 |
os.fchown(fd, uid, gid) | 修改一个文件的所有权,这个函数修改一个文件的用户ID和用户组ID,该文件由文件描述符fd指定 |
os.fdatasync(fd) | 强制将文件写入磁盘,该文件由文件描述符fd指定,但是不强制更新文件的状态信息。 |
os.fdopen(fd[, mode[, bufsize]]) | 通过文件描述符fd创建一个文件对象,并返回这个文件对象 |
os.fpathconf(fd, name) | 返回一个打开的文件的系统配置信息,name为检索的系统配置的值,它也许是一个定义系统值的字符串,这些名字在很多标准中指定(POSIX.1, Unix 95, Unix 98, 和其他) |
os.fstat(fd) | 返回文件描述符fd的状态,像stat() |
os.fstatvfs(fd) | 返回包含文件描述符fd的文件的文件系统的信息,Python3.3相当于statvfs() |
os.fsync(fd) | 强制将文件描述符为fd的文件写入硬盘 |
os.ftruncate(fd, length) | 裁剪文件描述符fd对应的文件,使他最大不能超过length大小 |
os.getcwd() | 返回当前工作目录 |
os.getcwdb() | 返回一个当前工作目录的Unicode对象 |
os.isatty(fd) | 如果文件描述符fd是打开的,同时与tty(-like)设备相连,则返回True,否则返回False |
os.lchflags(path, flags) | 设置路径的标记为数字标记,类似chflags(),但是没有软链接 |
os.lchmod(path, mode) | 修改链接文件权限 |
os.lchown(path, uid, gid) | 更改文件所有者,类似chown,但是不追踪链接 |
os.link(src, dst) | 创建硬链接,名为参数dst,指向参数src |
os.listdir(path) | 返回path指定的文件夹包含的文件或文件夹的名字的列表 |
os.lseek(fd, pos, how) | 设置文件描述符fd当前位置pos,how方式修改: SEEK_SET或者0设置从文件开始的计算的pos;SEEK_CUR或者1则从当前位置计算;os.SEEK_END或者2则从文件尾部开始,在unix,Windows中有效 |
os.lstat(path) | 如stat(),但是没有软链接 |
os.major(device) | 从原始的设备号中提取设备major号码(使用stat中的st_dev或者st_rdev field) |
os.makedev(major, minor) | 以major和minor设备号组成一个原始设备号 |
os.makedirs(path[, mode]) | 递归文件夹创建函数。如mkdir(),但创建的所有intermediate-level文件夹需要包含子文件夹 |
os.minor(device) | 从原始的设备号中提取设备minor号码(使用stat中的st_dev或st_rdev field) |
os.mkdir(path[, mode]) | 以数字mode的mode创建一个名为path的文件夹,默认的mode是0777(八进制) |
os.mkfifo(path[, mode]) | 创建命名管道,mode为数字,默认为0666(八进制) |
os.mknod(filename, mode=0600, device) | 创建一个名为filename文件系统节点(文件,设备特别文件或者命名pipe) |
os.open(file, flags[, mode]) | 打开一个文件,并且设置需要的打开选项,mode参数是可选的 |
os.openpty() | 打开一个新的伪终端,返回pty和tty的文件描述符 |
os.pathconf(path, name) | 返回相关文件的系统配置信息 |
os.pipe() | 创建一个管道,返回一对文件描述符(r, w)分别为读和写 |
os.popen(command[, mode[, bufsize]]) | 从一个command打开一个管道 |
os.read(fd, n) | 从文件描述符fd中读取最多n个字节,返回包含读取字节的字符串,文件描述符fd对应文件已达到结尾,返回一个空字符串 |
os.readlink(path) | 返回软链接所指向的文件 |
os.remove(path) | 删除路径为path的文件,如果path是一个文件夹,将抛出OSError;rmdir()将删除一个目录 |
os.removedirs(path) | 递归删除目录 |
os.rename(src, dst) | 重命名文件或目录,从src到dst |
os.renames(old, new) | 递归地对目录进行更名,也可以对文件进行更名 |
os.rmdir(path) | 删除path指定的空目录,如果目录非空,则抛出一个OSError异常 |
os.stat(path) | 获取path指定的路径信息,功能等同于C API中的stat()系统调用 |
os.stat_float_taimes([newvalue]) | 决定stat_result是否以float对象显示时间戳 |
os.statvfs(path) | 获取指定路径的文件系统统计信息 |
os.symlink(src, dst) | 创建一个软链接 |
os.tcgetpgrp(fd) | 返回与终端fd(一个由os.open()返回的打开的文件描述符)关联的进程组 |
os.tcsetpgrp(fd, pg) | 设置与终端fd(一个由os.open()返回的打开的文件描述符)关联的进程组为pg |
os.tempnam([dir[, prefix]]) | Python3中已删除。返回唯一的路径名用于创建临时文件 |
os.tmpfile() | Python3中已删除。返回一个打开模式为(w+b)的文件对象,该文件对象没有文件夹入口,没有文件描述符,将会自动删除 |
os.tmpnam() | Python3中已删除。为创建一个临时文件返回一个唯一的路径 |
os.ttyname(fd) | 返回一个字符串,它表示与文件描述符fd关联的终端设备。如果fd没有与终端设备关联,则引发一个异常 |
os.unlink(path) | 删除文件路径 |
os.utime(path, times) | 返回指定的path文件的访问和修改的时间 |
os.walk(top[, topdown=True[, onerror=None[, followlinks=False]]]) | 输出在文件夹中的文件名通过在树中游走,向上或者向下 |
os.write(fd, str) | 写入字符串到文件描述符fd中,返回实际写入的字符串长度 |
os.path模块 | 获取文件的属性信息 |
os.pardir() | 获取当前目录的父目录,以字符串形式显示目录名 |
os.replace() | 重命名文件或目录 |
os.startfile() | 用于在Windows上打开一个文件或文件夹 |
# Python3 错误和异常
Python有两种错误很容易辨认: 语法错误和异常。Python assert (断言)用于判断一个表达式,在表达式条件为False时触发异常。

# 语法错误
Python的语法错误或者称之为解析错:
>>> while True print('hello world')
File "<stdin>", line 1, in ?
while True print('hello world')
^
SyntaxError: invalid syntax
2
3
4
5
6
这个例子,函数print()被检查到有错误,前面缺少了一个冒号:。语法分析器指出了出错的一行,并且在最先找到的错误的位置标记了一个小小的箭头。
# 异常
即便Python程序语法正确,在运行时,也有可能发生错误。运行期间检测到的错误被称为异常。大多数的异常都不会被程序处理,都以错误的形式展现:
>>> 10 * (1/0) # 0 不能作为除数,触发异常
Traceback (most recent call last):
File "<stdin>", line 1, in ?
ZeroDivisionError: division by zero
>>> 4 + spam*3 # spam 未定义,触发异常
Traceback (most recent call last):
File "<stdin>", line 1, in ?
NameError: name 'spam' is not defined
>>> '2' + 2 # int 不能与 str 相加,触发异常
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: can only concatenate str (not "int") to str
2
3
4
5
6
7
8
9
10
11
12
13
14
异常以不同的类型出现,这些类型都作为信息的一部分打印出来: 例子中的类型有ZeroDivisionError,NameError和TypeError。错误信息的前面显示了异常发生的上下文,并以调用栈的形式显示具体信息。
# 异常处理
异常捕捉可以使用try/except语句。
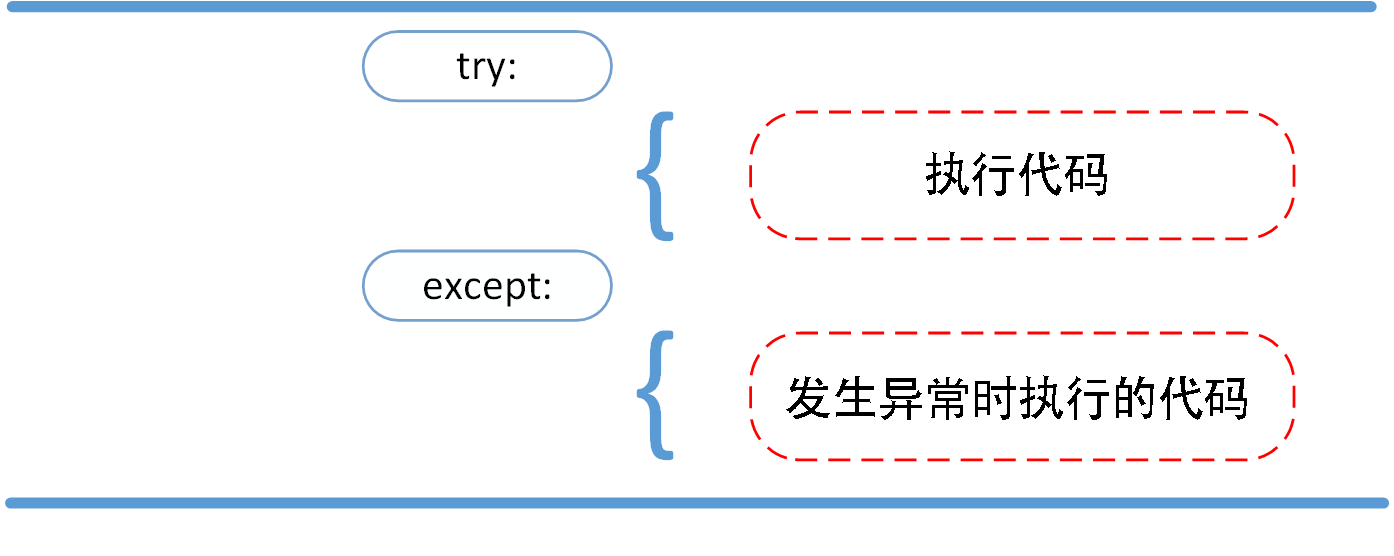
while True:
try:
x = int(input("请输入一个数字: "))
break
except ValueError:
print("您输入的不是数字,请再次尝试输入!")
2
3
4
5
6
以上实例,让用户输入一个合法的整数,但允许用户终端这个程序(使用Control-C或者操作系统提供的方法),用户终端的信息会引发一个KeyboardInterrupt异常。
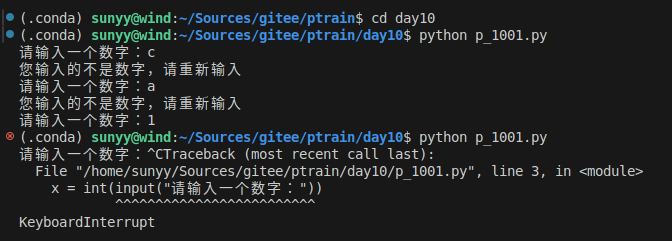
try语句按照如下方式工作:
- 首先,执行try子句(在关键字try和关键字except之间的语句)
- 如果没有异常发生,忽略except子句,try子句执行后结束
- 如果在执行try子句的过程中发生了异常,那么try子句余下的部分将被忽略,如果异常的类型和except之后的名称相符,那么对应的except子句将被执行。
- 如果一个异常没有与任何的except匹配,那么这个异常将会传递给上层的try中。
一个try语句可能包含多个except子句,分别来处理不同的特定的异常。最多只有一个分支会被执行。一个except可以同时处理多个异常,这些异常将被放在一个括号里称为一个元组:
except (RuntimeError, TypeError, NameError):
pass
2
最后一个except子句可以忽略异常的名称,它将被当做通配符使用,可以使用这种方式打印一个错误信息,然后再次把异常抛出。
import sys
try:
f = open('myfile.txt')
s = f.readline()
i = int(s.strip())
except OSError as err:
print("OS error: {0}".format(err))
except ValueError:
print("Could not convert data to an integer.")
except:
print("Unexpected error:", sys.exc_info()[0])
raise
2
3
4
5
6
7
8
9
10
11
12
13
try/except语句还有一个可选的else子句,如果使用这个子句,必须放在所有的except子句之后。else子句将在try子句没有发生任何异常的时候执行。

import sys
for arg in sys.argv[1:]:
try:
f = open(arg, 'r')
except OSError as err:
print('cannot open', arg)
else:
print(arg, 'has', len(f.readlines()), 'lines')
f.close()
2
3
4
5
6
7
8
9
10
11
使用else比把所有的语句都放在try里面好,可以避免一些意想不到,而except又无法捕获的异常。异常处理并不仅仅处理那些直接发生在try中的异常,还能处理子句中调用的函数(甚至间接调用的函数)里抛出的异常。
try-finally语句无论异常是否发生都会执行。
try:
print('try...。')
except AssertionError as error:
print(error)
else:
try:
with open('file.log') as file:
read_data = file.read()
except FileNotFoundError as fnf_error:
print(fnf_error)
finally:
print('这句话,无论异常是否发生都会执行。')
2
3
4
5
6
7
8
9
10
11
12
# 抛出异常
raise [Exception [, args[, traceback]]]
x = 10
if x > 5:
raise Exception('x 不能大于 5. x 的值为: {}'.format(x))
2
3
raise唯一的一个参数指定了要抛出的异常,它必须是一个异常的实例或者异常的类(也就是Exception的子类)。如果只想直到代码是否存在异常,并不真的处理它,一个简单的raise语句就可以再次抛出它。
try:
raise NameError('HiThere') # 模拟抛出异常
except NameError:
print('An exception flew by!')
raise
2
3
4
5
# 用户自定义异常
可以通过一个新的异常类来自定义异常,异常类继承自Exception类,可以直接继承或者间接继承,如:
class MyError(Exception):
def __init__(self, value):
self.value = value
def __str__(self):
return repr(self.value)
try:
raise MyError(2*2)
except MyError as e:
print('My exception occurred, value:', e.value)
2
3
4
5
6
7
8
9
10
在上面的例子中,类Exception默认的__init__()被覆盖,当创建一个模块有可能抛出多种不同的异常时,一种通常的做法是为这个包建立一个基础异常类,然后基于这个基础类为不同的错误情况创建不同的子类:
class Error(Exception):
"""Base class for exceptions in this module."""
pass
class InputError(Error):
"""Exception raised for errors in the input.
Attributes:
expression -- input expression in which the error occured
message -- explanation of the error
"""
def __init__(self, expression, message):
self.expression = expression
self.message = message
class TransitionError(Error):
"""Raised when an operation attempts a state transition that's not allowed.
Attributes:
previous -- state at beginning of transition
next -- attempted new state
message -- explanation of why the specific transition is not allowed
"""
def __init__(self, previous, next, message):
self.previous = previous
self.next = next
self.message = message
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# 定义清理行为
try:
raise KeyboardInterrupt
finally:
print('Goodby, world!')
2
3
4
以上例子不管try子句里面有没有发生异常,finally子句都会执行。如果一个异常在try子句里(或者在except和else子句里)被抛出,而又没有任何的except把它截住,那么这个异常会在finally子句执行后被抛出。
# 预定义的清理行为
一些对象定义了标准的清理行为,无论系统是否成功的使用了它,一旦不需要它了,那么这个标准的清理行为就会执行。
for line in open("myfile.txt"):
print(line, end="")
2
以上这段代码的问题是,当执行完毕后,文件会保持打开状态,并没有被关闭。关键词with语句可以保证诸如文件之类的对象在使用之后一定会正确的执行他的清理方法:
with open("myfile.txt") as f:
for line in f:
print(line, end="")
2
3
以上代码,即使处理过程出现了问题,最后文件f总是关闭状态。
# 相关内容
# Python assert (断言)
Python assert (断言)用于判断一个表达式,在表达式条件为False的时候触发异常。断言可以在条件不满足程序运行的情况下直接返回错误,而不必等待程序运行后出现崩溃的情况。

# 语法
assert expression
# 等价于
if not expression:
raise AssertionError
# assert后面也可以紧跟参数:
assert expression [, arguments]
# 等价于
if not expression:
raise Assertion(arguments)
2
3
4
5
6
7
8
9
10
assert True # 条件为 True 正常执行
assert False # 条件为 False 触发异常
assert 1==1 # 条件为 True 正常执行
assert 1==2 # 条件为 False 触发异常
2
3
4
# Python with (关键字)
Python中的with语句用于异常处理,封装了try...except...finally编码范式,提高了易用性。with语句使代码更清晰、更具可读性,简化了文件流等公共资源的管理。
file = open('./test_runoob.txt', 'w')
file.write('hello world!')
file.close()
2
3
以上代码如果在调用write的过程中,出现了异常,则close方法将无法被执行,因此资源就会一直被该程序占用而无法被释放。
file = open('./test_runoob.txt', 'w')
try:
file.writef('hello world')
finally:
file.close()
2
3
4
5
以上代码对可能发生异常的代码进行捕获,发生异常执行except代码块,finally代码块无论什么情况都会执行,因此文件会被关闭,不会因为执行异常而占用资源。
with open('./test_runoob.txt', 'w') as file:
file.write('hello world!')
2
使用with关键字系统会自动调用f.close()方法,with的作用等效于try/finally语句一样。with语句实现原理建立在上下文管理器之上,上下文管理器是一个实现__enter__和__exit__方法的类。使用with语句确保在嵌套块的末尾调用__exit__方法。在文件对象中定义了__enter__和__exit__方法,即文件对象也实现了上下文管理器,首先调用__enter__方法,然后执行with语句中的代码,最后调用__exit__方法,即使出现异常,也会调用__exit__方法,也就是关闭文件流。
实例: 以下实例代码是一个简单的文件读取工具,功能如下
- 读取城市列表: 从文件中读取以数字开头的城市名称,添加到旅游计划列表中
- 删除城市: 用户可以输入不想去的城市数量和序号,将对应的城市从计划中删除
- 修改城市: 用户可以选择修改某些城市的名称,更新旅游计划
- 生成随机旅游计划: 打乱城市顺序,并显示前五个城市作为最终的旅游推荐。
from random import shuffle
try:
with open('/home/sunyy/Sources/gitee/ptrain/5A.txt', 'r') as f:
i = [line for line in f if line[0].isdigit()]
except:
print("文件 '5A.txt' 不存在。")
exit()
travelList = []
# 添加旅游城市
for index, item in enumerate(i):
temp_1 = item.strip()[3:] # 使用 strip 去除行末的换行符
temp_1 = f"{index}#{temp_1}"
travelList.append(temp_1)
print("旅游计划城市: ", travelList)
# 删除旅游城市
city_num = input("请输入要删除的城市个数: ")
try:
for _ in range(int(city_num)):
index = int(input("请输入要删除的城市编号(第1个城市索引为0): "))
if 0 <= index < len(travelList):
travelList.pop(index)
print("旅游计划城市: ", travelList)
else:
print("输入的城市编号超出范围。")
except ValueError:
print("输入的城市编号不是整数。")
# 修改城市
city_num = input("输入修改计划旅游的城市个数: ")
try:
for _ in range(int(city_num)):
index = int(input("请输入要修改的城市编号(第1个城市索引为0): "))
if 0 <= index < len(travelList):
city_name = input("请输入新的城市名称: ")
travelList[index] = city_name
print("旅游计划城市: ", travelList)
else:
print("输入的城市编号超出范围。")
except ValueError:
print("输入的城市编号不是整数。")
shuffle(travelList)
print("请领取您的TOP5旅游城市: ", travelList[:5])
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
# Python3 面向对象
# 面向对象技术简介
- 类(Class): 用来描述具有相同的属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。对象是类的实例。
- 方法: 类中定义的函数。
- 类变量: 类变量在整个实例化的对象中是公用的。类变量定义在类中且在函数体之外,类变量通常不作为实例变量使用。
- 数据成员: 类变量或实例变量用于处理类及其实例对象的相关的数据。
- 方法重写: 如果从父类继承的方法不能满足子类的需求,可以对其进行改写,这个过程叫方法的覆盖(override),也称为方法的重写。
- 局部变量: 定义在方法中的变量,只作用域当前实例的类。
- 实例变量: 在类的声明中,属性是用变量来表示的,这种变量就称为实例变量,实例变量就是一个用self修饰的变量。
- 继承: 即一个派生类(derived class)继承基类(base class)的字段和方法。继承也允许把一个派生类的对象作为一个基类对象对待。
- 实例化: 创建一个类的实例,类的具体对象。
- 对象: 通过类定义的数据结构实例。对象包括两个数据成员(类变量和实例变量)和方法。
Python中的类提供了面向对象编程的所有基本功能: 类的继承机制允许多个基类,派生类可以覆盖基类中的任何方法,方法中可以调用基类中的同名方法。对象可以包含任意数量和类型的数据。
# 类定义
class ClassName:
<statement-1>
.
.
.
<statement-N>
2
3
4
5
6
类实例化后,可以使用其属性,实际上,创建一个类之后,可以通过类名访问其属性。
# 类对象
类对象支持两种操作: 属性引用和实例化。属性引用使用和Python中所有的属性引用一样的标准语法: obj.name。类对象创建后,类命名空间中所有的命名都是有效属性名。
class MyClass:
"""一个简单的类实例"""
i = 12345
def f(self):
return 'hello world'
# 实例化类
x = MyClass()
# 访问类的属性和方法
print("MyClass 类的属性 i 为:", x.i)
print("MyClass 类的方法 f 输出为:", x.f())
2
3
4
5
6
7
8
9
10
11
12

类有一个名为__init__()的特殊方法(构造方法),该方法在类实例化时会自动调用,如:
def __init__(self):
self.data = []
2
类定义了__init__()方法,类的实例化操作会自动调用该方法,如: x = MyClass()
而且,__init__()方法可以有参数,参数通过__init__()传递到类的实例化操作上,如:
class Complex:
def __init__(self, realpart, imagpart):
self.r = realpart
self.i = imagpart
x = Complex(3.0, -4.5)
print(x.r, x.i) # 输出结果:3.0 -4.5
2
3
4
5
6
7
self代表类的实例,而非类: 类的方法与普通的函数只有一个特别的区别--它们必须有一个额外的第一个参数名称,按照惯例它的名称是self。
class Test:
def prt(self):
print(self)
print(self.__class__)
t = Test()
t.prt()
2
3
4
5
6
7

从执行结果可以很明显的看出,self代表的是类的实例,代表当前对象的地址,而self.class则指向类。self不是python关键字,把他换成runoob也是可以正常执行的。
class Test:
def prt(runoob):
print(runoob)
print(runoob.__class__)
t = Test()
t.prt()
2
3
4
5
6
7
在Python中,self是一个惯用的名称,用于表示类的实例(对象)自身,它是一个指向实例的引用,使得类的方法能够访问和操作实例的属性。当定义一个类,并在类中定义方法时,第一个参数通常被命名为self,尽管可以使用其他名称,但强烈建议使用self,以保持代码的一致性和可读性。
class MyClass:
def __init__(self, value):
self.value = value
def display_value(self):
print("Value is:", self.value)
# 创建一个类的实例
obj = MyClass(100)
# 调用实例的方法
obj.display_value() # 输出 100
2
3
4
5
6
7
8
9
10
11
12
在上面的例子中,self是一个指向类实例的引用,它在__init__构造函数中用于初始化实例的属性,也在display_value方法中用于访问实例的属性。通过使用self,可以在类的方法中访问和操作实例的属性,从而实现类的行为。
# 类的方法
在类的内部,使用def关键字来定义一个方法,与一般函数定义不同,类方法必须包含参数self,且为第一个参数,self代表的是类的实例。
# 类定义
class people:
# 定义基本属性
name = ''
age = 0
# 定义私有属性,私有属性在类外部无法直接进行访问
__weight = 0
# 定义构造方法
def __init__(self,n,a,w):
self.name = n
self.age = a
self.__weight = w
def speak(self):
print("%s 说: 我 %d 岁。" %(self.name,self.age))
# 实例化类
p = people('runoob',10,30)
p.speak()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 继承
Python同样支持继承,派生类定义如下所示:
class DerivedClassName(BaseClassName):
<statement-1>
.
.
.
<statement-N>
2
3
4
5
6
子类(派生类DerivedClassName)会继承父类(基类BaseClassName)的属性和方法。BaseClassName(实例中的基类名)必须与派生类定义在一个作用域内,除了类,还可以使用表达式,基类定义在另一个模块中时非常有用。
# 类定义
class people:
# 定义基本属性
name = ''
age = 0
# 定义私有属性,私有属性在类外部无法直接进行访问
__weight = 0
# 定义构造方法
def __init__(self,n,a,w):
self.name = n
self.age = a
self.__weight = w
def speak(self):
print("%s 说: 我 %d 岁。" %(self.name,self.age))
# 单继承示例
class student(people):
grade = ''
def __init__(self,n,a,w,g):
# 调用父类的构函
people.__init__(self,n,a,w)
self.grade = g
# 覆写父类的方法
def speak(self):
print("%s 说: 我 %d 岁了,我在读 %d 年级"%(self.name,self.age,self.grade))
s = student('ken',10,60,3)
s.speak()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# 多继承
Python同样有限的支持多继承形式,多继承的类定义如下:
class DerivedClassName(Base1, Base2, Base3):
<statement-1>
.
.
.
<statement-N>
2
3
4
5
6
需要注意圆括号中父类的顺序,若是父类中有相同的方法名,而在子类使用时未指定,python从左至右搜索。即方法在子类中为找到时,从左到右查找父类中是否包含方法。
# 类定义
class people:
# 定义基本属性
name = ''
age = 0
# 定义私有属性,私有属性在类外部无法直接进行访问
__weight = 0
# 定义构造方法
def __init__(self,n,a,w):
self.name = n
self.age = a
self.__weight = w
def speak(self):
print("%s 说: 我 %d 岁。" %(self.name,self.age))
# 单继承示例
class student(people):
grade = ''
def __init__(self,n,a,w,g):
# 调用父类的构函
people.__init__(self,n,a,w)
self.grade = g
# 覆写父类的方法
def speak(self):
print("%s 说: 我 %d 岁了,我在读 %d 年级"%(self.name,self.age,self.grade))
# 另一个类,多重继承之前的准备
class speaker():
topic = ''
name = ''
def __init__(self,n,t):
self.name = n
self.topic = t
def speak(self):
print("我叫 %s,我是一个演说家,我演讲的主题是 %s"%(self.name,self.topic))
# 多继承
class sample(student,speaker):
a =''
def __init__(self,n,a,w,g,t):
student.__init__(self,n,a,w,g)
speaker.__init__(self,n,t)
test = sample("Tim",25,80,4,"Python")
test.speak() # 方法名同,默认调用的是在括号中排前地父类的方法
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45

# 方法重写
如果父类方法不能满足需求,可以在子类中重写父类的方法,如下:
class Parent: # define parent class
def myMethod(self):
print('Calling parent method')
class Child(Parent): # define child class
def myMethod(self):
print('Calling child method')
c = Child() # instance of child
c.myMethod() # child calls overridden method
super(Child, c).myMethod() # calls parent method
2
3
4
5
6
7
8
9
10
11

# 类属性与方法
# 类的私有属性
__private_attr: 两个下划线开头,声明该属性为私有,不能在类的外部被使用或直接访问,在类内部的方法中使用时self.__private_attr。
# 类的方法
在类的内部,使用def关键字来定义一个方法,与一般函数定义不同,类方法必须包含参数self,且为第一个参数,self代表的是类的实例。self的名字并不是规定死的,也可以使用this,但是最好还是以约定使用self。
# 类的私有方法
__private_method: 两个下划线开头,声明该方法为私有方法,只能在类的内部调用,不能在类的外部调用。self.__private_method。
类的私有属性实例如下:
class JustCounter:
__secretCount = 0
publicCount = 0
def count(self):
self.__secretCount += 1
self.publicCount += 1
print(self.__secretCount)
counter = JustCounter()
counter.count()
counter.count()
print(counter.publicCount)
print(counter.__secretCount) # 报错,实例不能访问私有变量
2
3
4
5
6
7
8
9
10
11
12
13
14
类的私有方法实例如下:
class Site:
def __init__(self, name, url):
self.name = name # public
self.__url = url # private
def who(self):
print('name : ', self.name)
print('url : ', self.__url)
def __foo(self): # 私有方法
print('这是私有方法')
def foo(self): # 公共方法
print('这是公共方法')
self.__foo()
x = Site('菜鸟教程', 'www.runoob.com')
x.who() # 正常输出
x.foo() # 正常输出
x.__foo() # 报错
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 类的专有方法
__init__: 构造函数,在生成对象时调用__del__: 析构函数,释放对象时使用__repr__: 打印,转换__setitem__: 按照索引赋值__getitem__: 按照索引获取值__len__: 获得长度__cmp__: 比较运算__call__: 函数调用__add__: 加运算__sub__: 减运算__mul__: 乘运算__truediv__: 除运算__mod__: 求余运算__pow__: 乘方
# 运算符重载
Python同样支持运算符重载,可以对类的专有方法进行重载,如:
class Vector:
def __init__(self, a, b):
self.a = a
self.b = b
def __str__(self):
return 'Vector (%d, %d)' % (self.a, self.b)
def __add__(self, other):
return Vector(self.a + other.a, self.b + other.b)
v1 = Vector(2, 10)
v2 = Vector(5, -2)
print(v1 + v2) # 输出结果:Vector(7, 8)
2
3
4
5
6
7
8
9
10
11
12
13
14
# Python3 命名空间和作用域
# 命名空间
A namespace is a mapping from names to objects. Most namespaces are currently implemented as Python dictionaries.
命名空间(Namespace)是从名称到对象的映射,大部分的命名空间都是通过Python字典来实现的。命名空间提供了在项目中避免名字冲突的一种方法。各个命名空间是独立的,没有任何关系,所以一个命名空间中不能有重名,但不同的命名空间是可以重名而没有任何影响。
比如:
一般有三种命名空间:
- 内置名称(built-in names): Python语言内置的名称,比如函数名abs, char和异常名称BaseException, Exception等等。
- 全局名称(global names): 模块中定义的名称,记录了模块的变量,包括函数、类、其它导入的模块、模块级的变量和常量。
- 局部名称(local names): 函数中定义的名称,记录了函数的变量,包括函数的参数和局部定义的变量。(类中定义的也是)
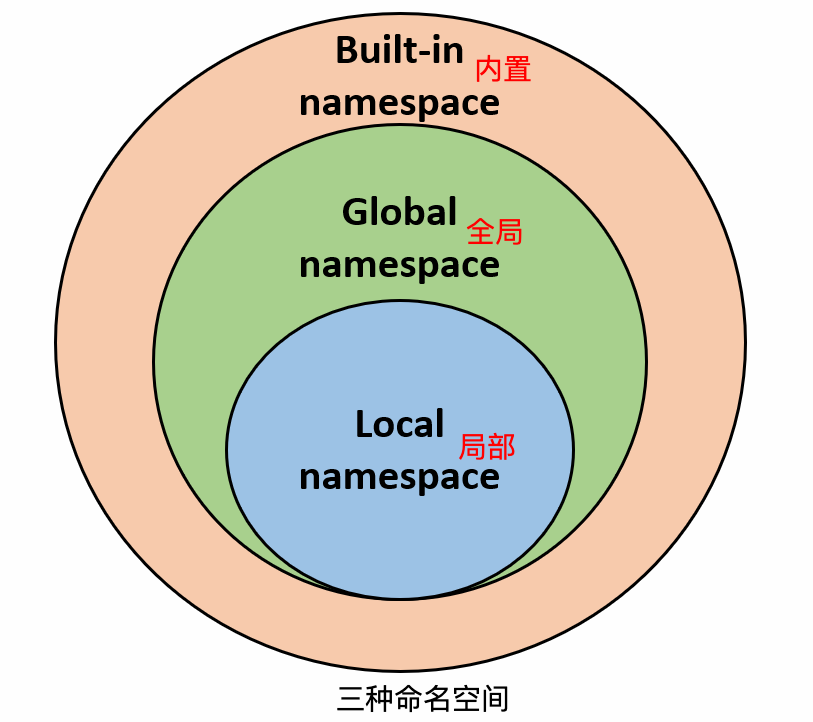
命名空间查找顺序: 假设要使用变量runoob,则Python的查找顺序为,局部的命名空间->全局命名空间->内置命名空间。如果找不到变量runoob,它将放弃查找并引发一个NameError异常。
NameError: name 'runoob' is not defined.
命名空间的声明周期: 命名空间的生命周期取决于对象的作用域,如果对象执行完成,则该命名空间的生命周期就结束,因此,无法从外部命名空间访问内部命名空间的对象。
# var1 是全局名称
var1 = 5
def some_func():
# var2 是局部名称
var2 = 6
def some_inner_func():
# var3 是内嵌的局部名称
var3 = 7
2
3
4
5
6
7
8
# 作用域
A scope is a textual region of a Python program where a namespace is directly accessible. "Directly accessible" here means that an unqualified reference to a name attempts to find the name in the namespace.
作用域就是一个Python程序可以直接访问命名空间的正文区域。在一个Python程序中,直接访问一个变量,会从内到外依次访问所有的作用域直到找到,否则会报未定义的错误。Python中,程序的变量并不是在哪个位置都可以访问的,访问权限决定于这个变量是在哪里赋值的。变量的作用域决定了在哪一部分程序可以访问哪个特定的变量名称。
Python的作用域一共有4种,分别是:
- L(Local): 最内层,包含局部变量,比如一个函数/方法内部。
- E(Enclosing): 包含了非局部(non-local)也非全局(non-global)的变量。比如两个嵌套函数,一个函数(或类)A里面又包含了一个函数B,那么对于B中的名称来说A中的作用域就为Enclosing。
- G(Global): 当前脚本的最外层,比如当前模块的全局变量。
- B(Built-in): 包含了内建的变量/关键字等,最后被搜索。
LEGB规则(Local, Enclosing, Global, Built-in): Python查找变量时的顺序是: L -> E -> G -> B。
- Local: 当前函数的局部作用域。
- Enclosing: 包含当前函数的外部函数的作用域(如果有嵌套函数)。
- Global: 当前模块的全局作用域。
- Built-in: Python内置的作用域。
在局部找不到,便会去局部外的局部找(例如闭包),再找不到就会去全局找,再者去内置中找。

g_count = 0 # 全局作用域
def outer():
o_count = 1 # 闭包函数外的函数中
def inner():
i_count = 2 # 局部作用域
2
3
4
5
内置作用域是通过一个名为builtin的标准模块来实现的,但是这个变量名自身并没有放入内置作用域内,所以必须导入这个文件才能够使用它。在Python3.0中,可以使用以下的代码来查看到底预定义了哪些变量:
>>> import builtins
>>> dir(builtins)
2
Python中只有模块(module),类(class)以及函数(def, lambda)才会引入新的作用域,其它的代码块(如if/elif/else, try/except, for/while等)是不会引入新的作用域的,也就是说这些语句内定义的变量,外部也可以访问,如下:
>>> if True:
... msg = 'I am from Runoob'
...
>>> msg
'I am from Runoob'
>>>
2
3
4
5
6
实例中msg变量定义在if语句块中,但外部还是可以访问的。如果将msg定义在函数中,则它就是局部变量,外部不能访问:
>>> def test():
... msg_inner = 'I am from Runoob'
...
>>> msg_inner
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'msg_inner' is not defined
2
3
4
5
6
7
从报错的信息看,说明了msg_inner未定义,无法使用,因为它是局部变量,只有在函数内可以使用。
# 全局变量和局部变量
定义在函数内部的变量拥有一个局部作用域,定义在函数外的拥有全局作用域。局部变量只能在其被声明的函数内部访问,而全局变量可以在整个程序范围内访问。在函数内部声明的变量只在函数的作用域中有效,调用函数时,这些内部变量会被加入到函数内部的作用域中,并且不会影响到函数外部的同名变量,如下:
total = 0 # 这是一个全局变量
# 可写函数说明
def sum(arg1, arg2):
# 返回2个参数的和
total = arg1 + arg2 # total在这里是局部变量
print("函数内是局部变量: ", total)
return total
# 调用sum函数
sum(10, 20)
print("函数外是全局变量: ", total)
2
3
4
5
6
7
8
9
10
11

- 全局变量: 在函数外部定义的变量,可以在整个文件中被访问。在函数外部定义的变量对所有函数都是可见的,除非函数内部定义了同名的局部变量。
x = 10 # 全局变量
def my_function():
print(x) # 可以访问全局变量 x
my_function() # 输出 10
2
3
4
5
6
- 局部变量: 在函数内部定义的变量,仅在函数内有效,函数外无法访问。局部变量优先级高于全局变量,因此如果局部变量和全局变量同名,函数内部会使用局部变量。
def my_function():
x = 5 # 局部变量
print(x) # 访问局部变量 x
my_function() # 输出 5
print(x) # 报错: NameError: name 'x' is not defined
2
3
4
5
6
# global 和 nonlocal 关键字
当内部作用域想修改外部作用域的变量时,就要用到global和nonlocal关键字。以下实例修改全局变量num:
num = 1
def fun1():
global num # 需要使用global关键字声明
print(num)
num = 123
print(num)
fun1()
print(num)
2
3
4
5
6
7
8
9

如果要修改嵌套作用域(enclosing作用域,外层非全局作用域)中的变量则需要nonlocal关键字,如:
def outer():
num = 10
def inner():
nonlocal num # nonlocal关键字声明
num = 100
print(num)
inner()
print(num)
outer()
2
3
4
5
6
7
8
9

另外有一种特殊情况,假设下面这段代码被运行:
a = 10
def test():
a = a + 1
print(a)
test()
2
3
4
5
以上程序执行,报错信息如下:
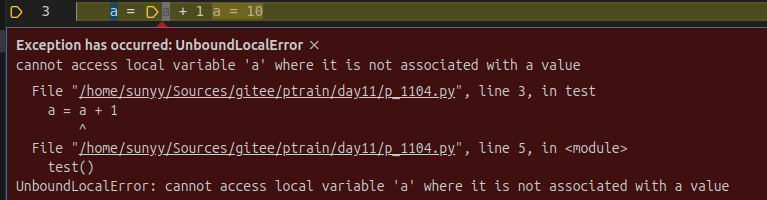
错误信息为局部作用域引用错误,因为test函数中的a使用的是局部,未定义,无法修改。需要修改a为全局变量:
a = 10
def test():
global a
a = a + 1
print(a)
test()
2
3
4
5
6
也可以通过函数参数传递:
a = 10
def test(a):
a = a + 1
print(a)
test(a)
2
3
4
5
# 总结
- 全局变量在函数外部定义,可以在整个文件中访问
- 局部变量在函数内部定义,只能在函数内访问。
- 使用global可以在函数中修改全局变量
- 使用nonlocal可以在嵌套函数中修改外部函数的变量
# Python3 标准库概览
Python标准库非常庞大,所提供的组件涉及范围十分广泛,使用标准库可以轻松完成各种任务。以下是一些Python3标准库中的模块:
- os模块: os模块提供了许多与操作系统交互的函数,例如创建、移动和删除文件和目录,以及访问环境变量等。
- sys模块: 提供了与Python解释器和系统相关的功能,例如解释器的版本和路径,以及与stdin、stdout和stderr相关的信息。
- time模块: 提供了处理时间的函数,例如获取当前时间、格式化日期和时间、计时等。
- datetime模块: 提供了更高级的日期和时间处理函数,例如处理时区、计算时间差、计算日期差等。
- random模块: 提供了生成随机数的函数,例如生成随机整数、浮点数、序列等。
- math模块: 提供了数学函数,例如三角函数、对数函数、指数函数、常数等。
- re模块: 提供了正则表达式处理函数,可以用于文本搜索、替换、分隔等。
- json模块: 提供了JSON编码和解码函数,可以将Python对象转换为JSON格式,并从JSON格式中解析除Python对象。
- urllib模块: 提供了访问网页和处理URL功能,包括下载文件、发送POST请求、处理cookies等。
# 操作系统接口
os模块提供了不少与操作系统相关联的函数,例如文件和目录的操作。
import os
# 获取当前工作目录
current_dir = os.getcwd()
print("当前工作目录: ", current_dir)
# 列出目录下的文件
files = os.listdir(current_dir)
print("目录下的文件: ", files)
2
3
4
5
6
7
8
9
建议使用import os风格而非from os import *,这样可以保证随操作系统不同而有所变化的os.open()不会覆盖内置函数open()。在使用os这样的大型模块时内置的dir()和help()函数非常有用:

>>> import os
>>> dir(os)
<returns a list of all module functions>
>>> help(os)
<returns an extensive manual page created from the module's docstrings>
2
3
4
5
针对日常的文件和目录管理任务,:mod:shutil模块提供了一个易于使用的高级接口:
>>> import shutil
>>> shutil.copyfile('data.db', 'archive.db')
>>> shutil.move('/build/executables', 'installdir')
2
3
# 文件通配符
glob模块提供了一个函数用于从目录通配符搜索中生成文件列表:
>>> import glob
>>> glob.glob('*.py')
['primes.py', 'random.py', 'quote.py']
2
3
# 命令行参数
通用工具脚本经常调用命令行参数。这些命令行参数以链表形式存储于sys模块的argv变量。例如在命令行中执行python demo.py one two three后可以得到如下输出结果:
>>> import sys
>>> print(sys.argv)
['demo.py', 'one', 'two', 'three']
2
3
# 错误输出重定向和程序终止
sys还有stdin, stdout和stderr属性,即使在stdout被重定向时,后者也可以用于显示警告和错误信息。
>>> sys.stderr.write('Warning, log file not found starting a new one\n')
Warning, log file not found starting a new one
2
大多脚本的定向终止都使用sys.exit()。
# 字符串正则匹配
re模块为高级字符串处理提供了正则表达式工具。对于复杂的匹配和处理,正则表达式提供了简介、优化的解决方案:
>>> import re
>>> re.findall(r'\bf[a-z]*', 'which foot or hand fell fastest')
['foot', 'fell', 'fastest']
>>> re.sub(r'(\b[a-z]+) \1', r'\1', 'cat in the the hat')
'cat in the hat'
2
3
4
5
如果只需要简单的功能,应该首先考虑字符串方法,因为其简单,易于阅读和调试:
>>> 'tea for too'.replace('too', 'two')
'tea for two'
2
# 数学
math模块为浮点运算提供了对底层C函数库的访问:
>>> import math
>>> math.cos(math.pi / 4)
0.70710678118654757
>>> math.log(1024, 2)
10.0
2
3
4
5
random提供了生成随机数的工具。
>>> import random
>>> random.choice(['apple', 'pear', 'bannana'])
'apple'
>>> random.sample(range(100), 10) # sampling without replacement
[30, 83, 16, 4, 8, 81, 41, 50, 18, 33]
>>> random.random() # random float
0.17970987693706186
>>> random.randrange(6) # random integer chosen from range(6)
4
2
3
4
5
6
7
8
9
# 访问互联网
有几个模块用于访问互联网以及处理网络通信协议。其中最简单的两个是用于处理从urls接收的数据urllib.request以及用于发送电子邮件的smtplib:
>>> from urllib.request import urlopen
>>> for line in urlopen('http://tycho.usno.navy.mil/cgi-bin/timer.pl'):
line = line.decode('utf-8') # Decoding the binary data to text.
if 'EST' in line or 'EDT' in line: # look for Eastern Time
print(line)
<BR>Nov. 25, 09:43:32 PM EST
>>> import smtplib
>>> server = smptlib.SMTP('localhost')
>>> server.sendmail('soothsayer@example.org', 'jcaesar@example.org',)
"""To: jcaesar@example.org
From: soothsayer@example.org
Beware the Ides of March.
"""
>>> server.quit()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
注意第二个例子需要本地有一个在运行的邮件服务器。
# 日期和时间
datetime模块为日期和时间处理同时提供了简单和复杂的方法。支持日期和时间算法的同时,实现的重点放在更有效的处理和格式化输出。
import datetime
# 获取当前日期和时间
current_datetime = datetime.datetime.now()
print(current_datetime)
# 获取当前日期
current_date = datetime.date.today()
print(current_date)
# 格式化日期
formatted_datetime = current_datetime.strftime("%Y-%m-%d %H:%M:%S")
print(formatted_datetime) # 输出: 2023-07-17 15:30:45
2
3
4
5
6
7
8
9
10
11
12
13
该模块还支持时区处理:
>>> # 导入了 datetime 模块中的 date 类
>>> from datetime import date
>>> now = date.today() # 当前日期
>>> now
datetime.date(2023, 7, 17)
>>> now.strftime("%m-%d-%y. %d %b %Y is a %A on the %d day of %B.")
'07-17-23. 17 Jul 2023 is a Monday on the 17 day of July.'
>>> # 创建了一个表示生日的日期对象
>>> birthday = date(1964, 7, 31)
>>> age = now - birthday # 计算两个日期之间的时间差
>>> age.days # 变量age的days属性,表示时间差的天数
21535
2
3
4
5
6
7
8
9
10
11
12
13
# 数据压缩
以下模块直接支持通用的数据打包和压缩格式: zlib, gzip, bz2, zipfile, tarfile。
>>> import zlib
>>> s = b'witch which has which witches wrist watch'
>>> len(s)
41
>>> t = zlib.compress(s)
>>> len(t)
37
>>> zlib.decompress(t)
b'witch which has which witches wrist watch'
>>> zlib.crc32(s)
226805979
2
3
4
5
6
7
8
9
10
11
# 性能度量
有时需要了解解决同一问题的不同方法之间的性能差异,Python提供了一个度量工具,为这些问题提供了直接答案。例如,使用元组封装和拆封来交换元素看起来要比使用传统的方法要诱人,timeit证明了现代的方法更快。
>>> from timeit import timer
>>> Timer('t=a; a=b; b=t', 'a=1; b=2').timeit()
0.57535828626024577
>>> TImer('a,b=b,a', 'a=1; b=2').timeit()
0.54962537085770791
2
3
4
5
相对于timeit的细粒度,:mod:profile和pstats模块提供了针对更大代码块的时间度量工具。
# 测试模块
开发高质量软件的方法之一是为每一个函数开发测试代码,并且在开发过程中经常进行测试,doctest模块提供了一个工具,扫描模块并根据程序中内嵌的文档字符串执行测试。测试构造如同简单的将它的输出结果剪切并粘贴到文档字符串中。通过用户提供的例子,它强化了文档,允许doctest模块确认代码的结果是否与文档一致。
def average(values):
"""Computes the arithmetic mean of a list of numbers.
>>> print(average([20, 30, 70]))
40.0
"""
return sum(values) / len(values)
import doctest
doctest.testmod() # 自动验证嵌入测试
2
3
4
5
6
7
8
9
10
unittest模块不像doctest模块那么容易使用,不过它可以在一个独立的文件里提供一个更全面的测试集:
import unittest
class TestStatisticalFunctions(unittest.TestCase):
def test_average(self):
self.assertEqual(average([20, 30, 70]), 40.0)
self.assertEqual(round(average([1, 5, 7]), 1), 4.3)
self.assertRaises(ZeroDivisionError, average, [])
self.assertRaises(TypeError, average, 20, 30, 70)
unittest.main() # Calling from the command line invokes all tests
2
3
4
5
6
7
8
9
10
11
# 标准库文档
以上只是Python3标准库中的一部分模块,还有很多其他模块可以在官方文档中查看完整的标准库文档: https://docs.python.org/zh-cn/3/library/index.html
# Python3 模块/包/库
模块、包、库是Python项目组织的基石,理解它们不仅能写出更专业的代码,还能大幅提升开发效率。
# Python 模块: 代码组织的基本单位
模块是Python种最基础的组织单元,它能够将相关代码逻辑封装在一个文件中,使用模块可以避免代码重复,提高可维护性,让项目结构更加清晰。
每个.py文件就是一个模块,模块名就是文件名(不带.py后缀),模块中可以包含函数、类和变量定义,这些都可以被其他模块导入使用。
# math_operations.py (模块文件)
def add(a, b):
return a + b
def substract(a, b):
return a - b
2
3
4
5
6
# main.py (使用模块)
import math_operations
result = math_operations.add(5, 3)
print(result) # 输出: 8
2
3
4
5
# Python 包: 模块的容器
当项目规模增大,模块数量增多时,就需要更高级的组织方式--包。包是包含多个模块的目录,它通过目录结构来组织相关模块,是项目更加结构化。
一个包必须包含一个特殊的__init__.py文件(可以是空文件),Python通过这个文件识别目录为包。包可以嵌套,形成多层次的包结构。
# 项目结构
my_package/
├── __init__.py
├── module1.py
└── subpackage/
├── __init__.py
└── module2.py
2
3
4
5
6
7
# 使用包中的模块
from my_package.module1 import function1
from my_package.subpackage.module2 import function2
2
3
# Python 库: 可重用的代码集合
库是一个更广泛的概念,它指代一组可重用的代码,可以是一个模块、一个包或一组包。Python标准库是Python自带的库集合,而第三方库则是社区开发的扩展。
库通常解决特定领域的问题,如科学计算(Numpy), Web开发(Django)等。使用库可以避免重复造轮子,专注于业务逻辑开发。
# 使用标准库datetime
from datetime import datetime
now = datetime.now()
print(now.strftime("%Y-%m-%d %H:%M:%S"))
2
3
4
5
6
# 使用第三方库requests
import requests
response = requests.get("https://api.github.com")
print(response.status_code)
2
3
4
5
6
# 模块、包、库的关系与区别
模块是单个文件,包是包含模块的目录结构,而库则是更广泛的概念,可以包含一个或多个包和模块。
模块用于组织小规模代码,包用于组织大规模项目,而库则是为了代码重用和共享。标准库是随Python安装自带,第三方库需要通过pip等工具安装。
# 示例:标准库中的包和模块
import os.path # os是包,path是模块
from collections import defaultdict # collections是包,defaultdict是模块中的类
2
3
# 最佳实践: 如何组织 Python 项目
良好的项目结构能大大提高代码的可维护性和可扩展性,遵循PEP8和PEP20的原则,合理使用模块和包来组织代码。建议将相关功能放在同一模块中,将相关模块组织到同一包中。避免循环导入,合理使用__init__.py文件控制包的导入行为:
# 推荐的项目结构示例
my_project/
├── docs/ # 文档
├── tests/ # 测试代码
├── requirements.txt # 依赖列表
└── src/ # 源代码
├── __init__.py
├── main.py # 入口点
├── core/ # 核心功能包
│ ├── __init__.py
│ ├── utils.py
│ └── models.py
└── helpers/ # 辅助功能包
├── __init__.py
└── logger.py
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 常见问题与解决方案
初学者在使用模块和包时常会遇到一些问题,如导入错误、循环依赖等。理解Python的导入机制和搜索路径是解决这些问题的关键。
使用相对导入时要注意执行环境,避免将模块命名为Python内置模块名。当遇到导入问题时,可以打印sys.path查看Python的模块搜索路径。
# 处理导入问题的技巧
import sys
print(sys.path) # 查看Python搜索模块的路径
# 添加自定义路径
sys.path.append("/path/to/your/module")
2
3
4
5
6
# Python3 实例
# Python3 测验
- Python3 教程
- 查看Python版本
- 第一个Python3.x程序
- Python3 简介
- Python 发展历史
- Python 特点
- Python 应用
- Python3 基础语法
- 编码
- 标识符
- Python 保留字
- 注释
- 行与缩进
- 多行语句
- 数字(Number)类型
- 字符串(String)
- 空行
- 等待用户输入
- 同一行显示多条语句
- 多个语句构成代码组
- print 输出
- import 与 from ... import
- Python3 基本数据类型
- 标准数据类型
- Number (数字)
- String (字符串)
- bool (布尔类型)
- List (列表)
- Tuple (元组)
- Set (集合)
- Dictionary (字典)
- bytes 类型
- Python3 数据类型转换
- 隐式类型转换
- 显式类型转换
- Python3 注释
- 拓展说明
- Python3 运算符
- 算术运算符
- 比较运算符
- 赋值运算符
- 位运算符
- 逻辑运算符
- 成员运算符
- 身份运算符
- 运算符优先级
- Python3 数字(Number)
- Python 数字类型转换
- Python 数字运算
- 数学函数
- 随机数函数
- 三角函数
- 数学常量
- Python3 字符串
- Python 访问字符串中的值
- Python 字符串更新
- Python 转义字符
- Python 字符串运算符
- Python 字符串格式化
- Python 三引号
- f-string
- Unicode字符串
- Python 的字符串内建函数
- Python3 列表
- 访问列表中的值
- 更新列表
- 删除列表元素
- Python列表脚本操作符
- Python列表截取与拼接
- 嵌套列表
- 列表比较
- Python列表函数&方法
- Python3 元组
- 访问元组
- 修改元组
- 删除元组
- 元组运算符
- 元组索引,截取
- 元组内置函数
- Python3 字典
- 创建空字典
- 访问字典里的值
- 修改字典
- 删除字典元素
- 字典内置函数&方法
- Python3 集合
- 集合的基本操作
- 集合内置方法完整列表
- Python3 条件控制
- if 语句
- if 嵌套
- match...case
- Python3 循环语句
- while 循环
- for 语句
- range() 函数
- break 和 continue 语句及循环中的 else 子句
- pass 语句
- Python3 编程第一步
- Python3 推导式
- 列表推导式
- 字典推导式
- 集合推导式
- 元组推导式
- Python3 迭代器与生成器
- 迭代器
- 生成器
- Python3 函数
- 定义一个函数
- 函数调用
- 参数传递
- 参数
- 匿名函数
- return 语句
- 强制位置参数
- Python3 lambda
- Python3 装饰器
- Python3 数据结构
- 列表
- 将列表当做栈使用
- 将列表当做队列使用
- 列表推导式
- 嵌套列表解析
- del 语句
- 元组和序列
- 集合
- 字典
- 遍历技巧
- Python3 模块
- import 语句
- from ... import 语句
- from ... import * 语句
- 深入模块
- __name__ 属性
- dir() 函数
- 标准模块
- 包
- 从一个包中导入*
- Python3 输入和输出
- 输出格式美化
- 旧式字符串格式化
- 读取键盘输入
- 读和写文件
- 文件对象的方法
- pickle 模块
- Python3 File
- open() 方法
- file 对象
- Python3 OS
- Python3 错误和异常
- 语法错误
- 异常
- 异常处理
- 抛出异常
- 用户自定义异常
- 定义清理行为
- 预定义的清理行为
- 相关内容
- Python3 面向对象
- 面向对象技术简介
- 类定义
- 类对象
- 类的方法
- 继承
- 多继承
- 方法重写
- 类属性与方法
- Python3 命名空间和作用域
- 命名空间
- 作用域
- 总结
- Python3 标准库概览
- 操作系统接口
- 文件通配符
- 命令行参数
- 错误输出重定向和程序终止
- 字符串正则匹配
- 数学
- 访问互联网
- 日期和时间
- 数据压缩
- 性能度量
- 测试模块
- 标准库文档
- Python3 模块/包/库
- Python 模块: 代码组织的基本单位
- Python 包: 模块的容器
- Python 库: 可重用的代码集合
- 模块、包、库的关系与区别
- 最佳实践: 如何组织 Python 项目
- 常见问题与解决方案
- Python3 实例
- Python3 测验